一. 前言
在前文中,我们分析了内核中进程和线程的统一结构体task_struct,本文将继续分析进程、线程的创建和派生的过程。首先介绍如何将一个程序编辑为执行文件最后成为进程执行,然后会介绍线程的执行,最后会分析如何通过已有的进程、线程实现多进程、多线程。因为进程和线程有诸多相似之处,也有一些不同之处,因此本文会对比进程和线程来加深理解和记忆。
二. 进程的创建
以C语言为例,我们在Linux下编写C语言代码,然后通过gcc编译和链接生成可执行文件后直接执行即可完成一个进程的创建和工作。下面将详细展开介绍这个创建进程的过程。在 Linux 下面,二进制的程序也要有严格的格式,这个格式我们称为 ELF(Executable and Linkable Format,可执行与可链接格式)。这个格式可以根据编译的结果不同,分为不同的格式。主要包括
可重定位的对象文件(Relocatable file)
由汇编器汇编生成的 .o 文件
可执行的对象文件(Executable file)
可执行应用程序
可被共享的对象文件(Shared object file)
动态库文件,也即 .so 文件
下面在进程创建过程中会详细说明三种文件。
2. 1 编译
写完C程序后第一步就是程序编译(其实还有IDE的预编译,那些属于编辑器操作这里不表)。编译指令如下所示
1 | gcc -c -fPIC xxxx.c |
-c表示编译、汇编指定的源文件,不进行链接。-fPIC表示生成与位置无关(Position-Independent Code)代码,即采用相对地址而非绝对地址,从而满足共享库加载需求。在编译的时候,先做预处理工作,例如将头文件嵌入到正文中,将定义的宏展开,然后就是真正的编译过程,最终编译成为.o 文件,这就是 ELF 的第一种类型,可重定位文件(Relocatable File)。之所以叫做可重定位文件,是因为对于编译好的代码和变量,将来加载到内存里面的时候,都是要加载到一定位置的。比如说,调用一个函数,其实就是跳到这个函数所在的代码位置执行;再比如修改一个全局变量,也是要到变量的位置那里去修改。但是现在这个时候,还是.o 文件,不是一个可以直接运行的程序,这里面只是部分代码片段。因此.o 里面的位置是不确定的,但是必须是可重新定位的以适应需求。
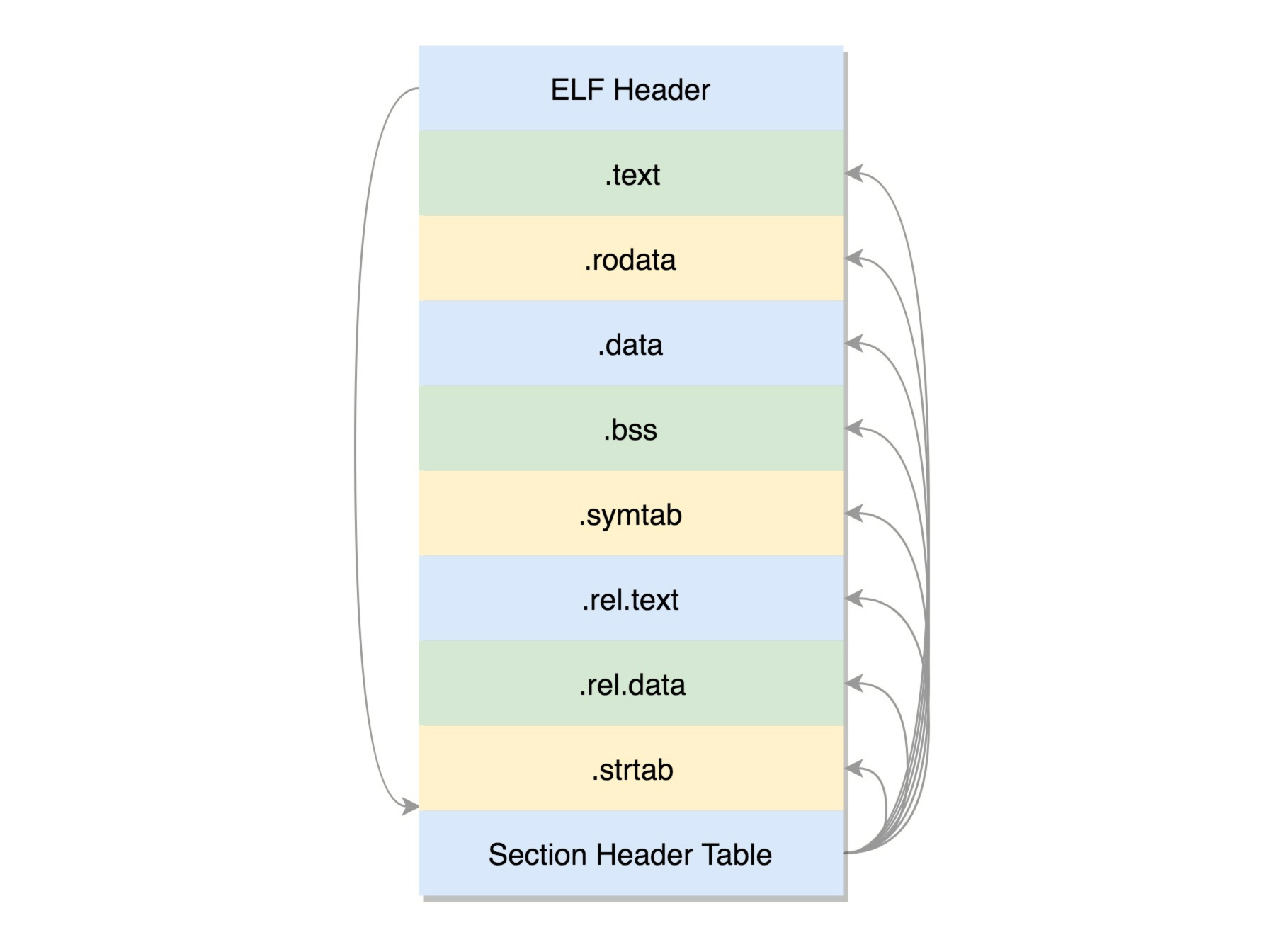
ELF 文件的头是用于描述整个文件的。这个文件格式在内核中有定义,分别为 struct elf32_hdr 和struct elf64_hdr。其他各个section作用如下所示
- .text:放编译好的二进制可执行代码
- .rodata:只读数据,例如字符串常量、const 的变量
- .data:已经初始化好的全局变量
- .bss:未初始化全局变量,运行时会置 0
- .symtab:符号表,记录的则是函数和变量
- .rel.text: .text部分的重定位表
- .rel.data:.data部分的重定位表
- .strtab:字符串表、字符串常量和变量名
这些节的元数据信息也需要有一个地方保存,就是最后的节头部表(Section Header Table)。在这个表里面,每一个 section 都有一项,在代码里面也有定义 struct elf32_shdr和struct elf64_shdr。在 ELF 的头里面,有描述这个文件的节头部表的位置,有多少个表项等等信息。
2.2 链接
链接分为静态链接和动态链接。静态链接库会和目标文件通过链接生成一个可执行文件,而动态链接则会通过链接形成动态连接器,在可执行文件执行的时候动态的选择并加载其中的部分或全部函数。二者的各自优缺点如下所示
静态链接库的优点
(1) 代码装载速度快,执行速度略比动态链接库快;
(2) 只需保证在开发者的计算机中有正确的.LIB文件,在以二进制形式发布程序时不需考虑在用户的计算机上.LIB文件是否存在及版本问题,可避免DLL地狱等问题。
静态链接库的缺点
使用静态链接生成的可执行文件体积较大,包含相同的公共代码,造成浪费
动态链接库的优点
(1) 更加节省内存并减少页面交换;
(2) DLL文件与EXE文件独立,只要输出接口不变(即名称、参数、返回值类型和调用约定不变),更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性;
(3) 不同编程语言编写的程序只要按照函数调用约定就可以调用同一个DLL函数;
(4)适用于大规模的软件开发,使开发过程独立、耦合度小,便于不同开发者和开发组织之间进行开发和测试。
动态链接库的缺点
使用动态链接库的应用程序不是自完备的,它依赖的DLL模块也要存在,如果使用载入时动态链接,程序启动时发现DLL不存在,系统将终止程序并给出错误信息。而使用运行时动态链接,系统不会终止,但由于DLL中的导出函数不可用,程序会加载失败;速度比静态链接慢。当某个模块更新后,如果新模块与旧的模块不兼容,那么那些需要该模块才能运行的软件均无法执行。这在早期Windows中很常见。
下面分别介绍静态链接和动态链接
2.2.1 静态链接
静态链接库.a文件(Archives)的执行指令如下
1 | ar cr libXXX.a XXX.o XXXX.o |
当需要使用该静态库的时候,会将.o文件从.a文件中依次抽取并链接到程序中,指令如下
1 | gcc -o XXXX XXX.O -L. -lsXXX |
-L表示在当前目录下找.a 文件,-lsXXXX会自动补全文件名,比如加前缀 lib,后缀.a,变成libXXX.a,找到这个.a文件后,将里面的 XXXX.o 取出来,和 XXX.o 做一个链接,形成二进制执行文件XXXX。在这里,重定位会从.o中抽取函数并和.a中的文件抽取的函数进行合并,找到实际的调用位置,形成最终的可执行文件(Executable file),即ELF的第二种格式文件。
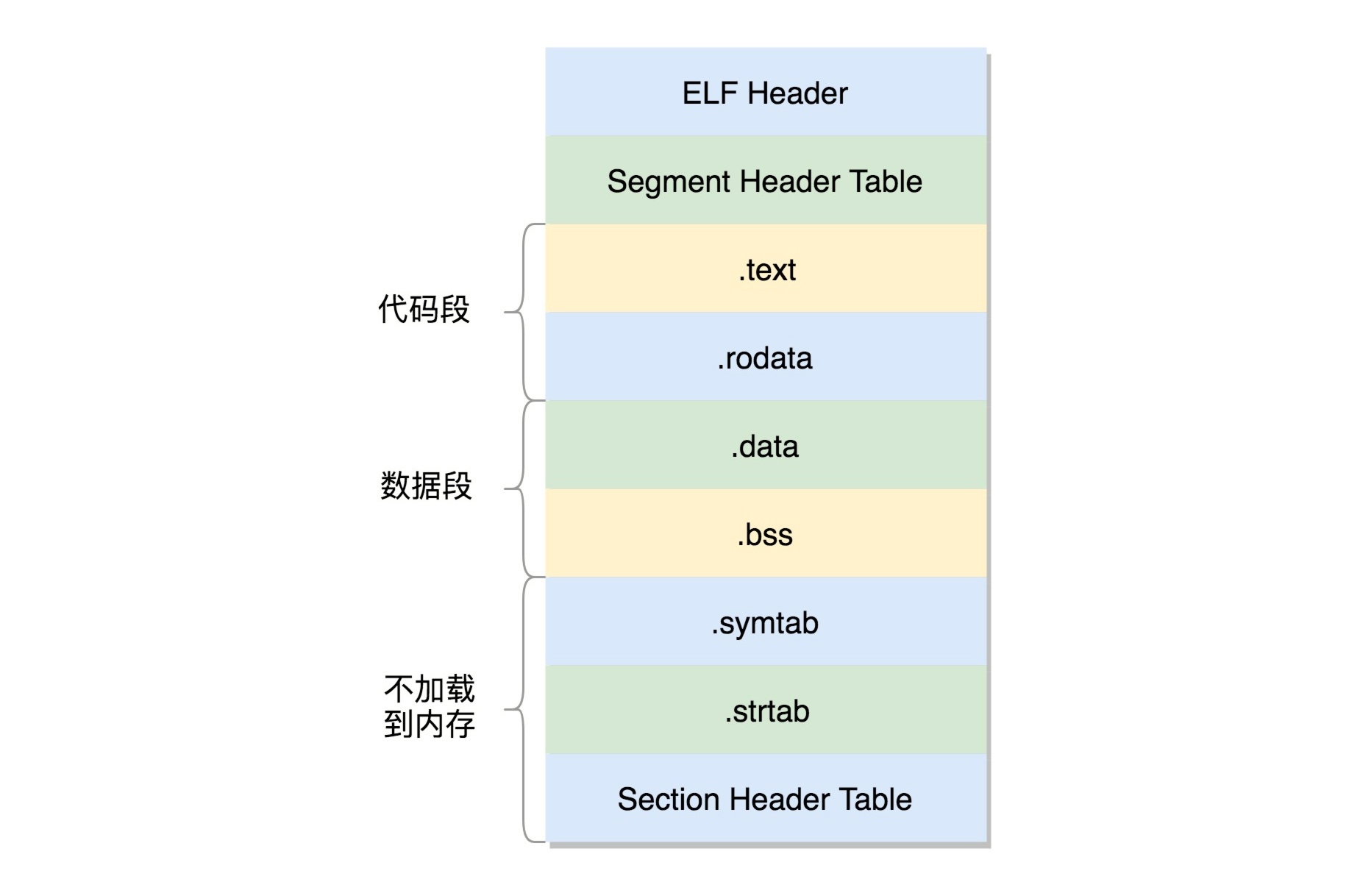
对比ELF第一种格式可重定位文件,这里可执行文件略去了重定位表相关段落。此处将ELF文件分为了代码段、数据段和不加载到内存中的部分,并加上了段头表(Segment Header Table)用以记录管理,在代码中定义为struct elf32_phdr和 struct elf64_phdr,这里面除了有对于段的描述之外,最重要的是 p_vaddr,这个是这个段加载到内存的虚拟地址。这部分会在内存篇章详细介绍。
2.2.2 动态链接
动态链接库(Shared Libraries)的作用主要是为了解决静态链接大量使用会造成空间浪费的问题,因此这里设计成了可以被多个程序共享的形式,其执行命令如下
1 | gcc -shared -fPIC -o libXXX.so XXX.o |
当一个动态链接库被链接到一个程序文件中的时候,最后的程序文件并不包括动态链接库中的代码,而仅仅包括对动态链接库的引用,并且不保存动态链接库的全路径,仅仅保存动态链接库的名称。
1 | gcc -o XXX XXX.O -L. -lXXX |
当运行这个程序的时候,首先寻找动态链接库,然后加载它。默认情况下,系统在 /lib 和/usr/lib 文件夹下寻找动态链接库。如果找不到就会报错,我们可以设定 LD_LIBRARY_PATH环境变量,程序运行时会在此环境变量指定的文件夹下寻找动态链接库。动态链接库,就是 ELF 的第三种类型,共享对象文件(Shared Object)。
动态链接的ELF相对于静态链接主要多了以下部分
.interp段,里面是ld-linux.so,负责运行时的链接动作.plt(Procedure Linkage Table),过程链接表.got.plt(Global Offset Table),全局偏移量表
当程序编译时,会对每个函数在PLT中建立新的项,如PLT[n],而动态库中则存有该函数的实际地址,记为GOT[m]。整体寻址过程如下所示
PLT[n]向GOT[m]寻求地址GOT[m]初始并无地址,需要采取以下方式获取地址- 回调
PLT[0] PLT[0]调用GOT[2],即ld-linux.sold-linux.so查找所需函数实际地址并存放在GOT[m]中
- 回调
由此,我们建立了PLT[n]到GOT[m]的对应关系,从而实现了动态链接。
2.3 加载运行
完成了上述的编译、汇编、链接,我们最终形成了可执行文件,并加载运行。在内核中,有这样一个数据结构,用来定义加载二进制文件的方法。
1 | struct linux_binfmt { |
对于ELF文件格式,其对应实现为
1 | static struct linux_binfmt elf_format = { |
其中加载的函数指针指向的函数和内核镜像加载是同一份函数,实际上通过exec函数完成调用。exec 比较特殊,它是一组函数:
- 包含 p 的函数
(execvp, execlp)会在 PATH 路径下面寻找程序;不包含 p 的函数需要输入程序的全路径; - 包含 v 的函数
(execv, execvp, execve)以数组的形式接收参数; - 包含 l 的函数
(execl, execlp, execle)以列表的形式接收参数; - 包含 e 的函数
(execve, execle)以数组的形式接收环境变量。
当我们通过shell运行可执行文件或者通过fork派生子类,均是通过该类函数实现加载。
三. 线程的创建之用户态
线程的创建对应的函数是pthread_create(),线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。pthread_create()不是一个系统调用,是 Glibc 库的一个函数,所以我们还要从 Glibc 说起。但是在开始之前,我们先要提一下,线程的创建到了内核态和进程的派生会使用同一个函数:__do_fork(),这也很容易理解,因为对内核态来说,线程和进程是同样的task_struct结构体。本节介绍线程在用户态的创建,而内核态的创建则会和进程的派生放在一起说明。
在Glibc的ntpl/pthread_create.c中定义了__pthread_create_2_1()函数,该函数主要进行了以下操作
- 处理线程的属性参数。例如前面写程序的时候,我们设置的线程栈大小。如果没有传入线程属性,就取默认值。
1 | const struct pthread_attr *iattr = (struct pthread_attr *) attr; |
- 就像在内核里每一个进程或者线程都有一个
task_struct结构,在用户态也有一个用于维护线程的结构,就是这个pthread结构。
1 | struct pthread *pd = NULL; |
- 凡是涉及函数的调用,都要使用到栈。每个线程也有自己的栈,接下来就是创建线程栈了。
1 | int err = ALLOCATE_STACK (iattr, &pd); |
ALLOCATE_STACK 是一个宏,对应的函数allocate_stack()主要做了以下这些事情:
- 如果在线程属性里面设置过栈的大小,则取出属性值;
- 为了防止栈的访问越界在栈的末尾添加一块空间
guardsize,一旦访问到这里就会报错; - 线程栈是在进程的堆里面创建的。如果一个进程不断地创建和删除线程,我们不可能不断地去申请和清除线程栈使用的内存块,这样就需要有一个缓存。
get_cached_stack就是根据计算出来的size大小,看一看已经有的缓存中,有没有已经能够满足条件的。如果缓存里面没有,就需要调用__mmap创建一块新的缓存,系统调用那一节我们讲过,如果要在堆里面malloc一块内存,比较大的话,用__mmap; - 线程栈也是自顶向下生长的,每个线程要有一个
pthread结构,这个结构也是放在栈的空间里面的。在栈底的位置,其实是地址最高位; - 计算出
guard内存的位置,调用setup_stack_prot设置这块内存的是受保护的; - 填充
pthread这个结构里面的成员变量stackblock、stackblock_size、guardsize、specific。这里的specific是用于存放Thread Specific Data的,也即属于线程的全局变量; - 将这个线程栈放到
stack_used链表中,其实管理线程栈总共有两个链表,一个是stack_used,也就是这个栈正被使用;另一个是stack_cache,就是上面说的,一旦线程结束,先缓存起来,不释放,等有其他的线程创建的时候,给其他的线程用。
1 |
|
四. 线程的内核态创建及进程的派生
多进程是一种常见的程序实现方式,采用的系统调用为fork()函数。前文中已经详细叙述了系统调用的整个过程,对于fork()来说,最终会在系统调用表中查找到对应的系统调用sys_fork完成子进程的生成,而sys_fork 会调用 _do_fork()。
1 | SYSCALL_DEFINE0(fork) |
关于__do_fork()先按下不表,再接着看看线程。我们接着pthread_create ()看。其实有了用户态的栈,接着需要解决的就是用户态的程序从哪里开始运行的问题。start_routine() 就是给线程的函数,start_routine(), 参数 arg,以及调度策略都要赋值给 pthread。接下来 __nptl_nthreads 加一,说明又多了一个线程。
1 | pd->start_routine = start_routine; |
真正创建线程的是调用 create_thread() 函数,这个函数定义如下。同时,这里还规定了当完成了内核态线程创建后回调的位置:start_thread()。
1 | static int |
在 start_thread() 入口函数中,才真正的调用用户提供的函数,在用户的函数执行完毕之后,会释放这个线程相关的数据。例如,线程本地数据 thread_local variables,线程数目也减一。如果这是最后一个线程了,就直接退出进程,另外 __free_tcb() 用于释放 pthread。
1 |
|
__free_tcb ()会调用 __deallocate_stack()来释放整个线程栈,这个线程栈要从当前使用线程栈的列表 stack_used 中拿下来,放到缓存的线程栈列表 stack_cache中,从而结束了线程的生命周期。
1 | void |
ARCH_CLONE其实调用的是 __clone()。
1 | # define ARCH_CLONE __clone |
内核中的clone()定义如下。如果在进程的主线程里面调用其他系统调用,当前用户态的栈是指向整个进程的栈,栈顶指针也是指向进程的栈,指令指针也是指向进程的主线程的代码。此时此刻执行到这里,调用 clone的时候,用户态的栈、栈顶指针、指令指针和其他系统调用一样,都是指向主线程的。但是对于线程来说,这些都要变。因为我们希望当 clone 这个系统调用成功的时候,除了内核里面有这个线程对应的 task_struct,当系统调用返回到用户态的时候,用户态的栈应该是线程的栈,栈顶指针应该指向线程的栈,指令指针应该指向线程将要执行的那个函数。所以这些都需要我们自己做,将线程要执行的函数的参数和指令的位置都压到栈里面,当从内核返回,从栈里弹出来的时候,就从这个函数开始,带着这些参数执行下去。
1 | SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, |
线程和进程到了这里殊途同归,进入了同一个函数__do_fork()工作。其源码如下所示,主要工作包括复制结构copy_process()和唤醒新进程wak_up_new()两部分。其中线程会根据create_thread()函数中的clone_flags完成上文所述的栈顶指针和指令指针的切换,以及一些线程和进程的微妙区别。
1 | long _do_fork(unsigned long clone_flags, |
4.1 任务结构体复制
如下所示为copy_process()函数源码精简版,task_struct结构复杂也注定了复制过程的复杂性,因此此处省略了很多,仅保留了各个部分的主要调用函数
1 |
|
copy_process()首先调用了dup_task_struct()分配task_struct结构,dup_task_struct()主要做了下面几件事情:
- 调用
alloc_task_struct_node分配一个task_struct结构; - 调用
alloc_thread_stack_node来创建内核栈,这里面调用__vmalloc_node_range分配一个连续的THREAD_SIZE的内存空间,赋值给task_struct的void *stack成员变量; - 调用
arch_dup_task_struct(struct task_struct *dst, struct task_struct *src),将task_struct进行复制,其实就是调用memcpy; - 调用
setup_thread_stack设置thread_info。
1 | static struct task_struct *dup_task_struct(struct task_struct *orig, int node) |
- 接着,调用
copy_creds处理权限相关内容
- 调用
prepare_creds,准备一个新的struct cred *new。如何准备呢?其实还是从内存中分配一个新的struct cred结构,然后调用memcpy复制一份父进程的 cred; - 接着
p->cred = p->real_cred = get_cred(new),将新进程的“我能操作谁”和“谁能操作我”两个权限都指向新的cred。
1 | /* |
- 设置调度相关的变量。该部分源码先不展示,会在进程调度中详细介绍。
sched_fork主要做了下面几件事情:
- 调用
__sched_fork,在这里面将on_rq设为 0,初始化sched_entity,将里面的exec_start、sum_exec_runtime、prev_sum_exec_runtime、vruntime都设为 0。这几个变量涉及进程的实际运行时间和虚拟运行时间。是否到时间应该被调度了,就靠它们几个; - 设置进程的状态
p->state = TASK_NEW; - 初始化优先级
prio、normal_prio、static_prio; - 设置调度类,如果是普通进程,就设置为
p->sched_class = &fair_sched_class; - 调用调度类的
task_fork函数,对于 CFS 来讲,就是调用task_fork_fair。在这个函数里,先调用update_curr,对于当前的进程进行统计量更新,然后把子进程和父进程的vruntime设成一样,最后调用place_entity,初始化sched_entity。这里有一个变量sysctl_sched_child_runs_first,可以设置父进程和子进程谁先运行。如果设置了子进程先运行,即便两个进程的vruntime一样,也要把子进程的sched_entity放在前面,然后调用resched_curr,标记当前运行的进程TIF_NEED_RESCHED,也就是说,把父进程设置为应该被调度,这样下次调度的时候,父进程会被子进程抢占。
- 初始化文件和文件系统相关变量
copy_files主要用于复制一个任务打开的文件信息。- 对于进程来说,这些信息用一个结构
files_struct来维护,每个打开的文件都有一个文件描述符。在 copy_files 函数里面调用dup_fd,在这里面会创建一个新的 files_struct,然后将所有的文件描述符数组fdtable拷贝一份。 - 对于线程来说,由于设置了
CLONE_FILES标识位变成将原来的files_struct引用计数加一,并不会拷贝文件。
- 对于进程来说,这些信息用一个结构
1 | static int copy_files(unsigned long clone_flags, struct task_struct *tsk) |
copy_fs主要用于复制一个任务的目录信息。- 对于进程来说,这些信息用一个结构
fs_struct来维护。一个进程有自己的根目录和根文件系统root,也有当前目录pwd和当前目录的文件系统,都在fs_struct里面维护。copy_fs函数里面调用copy_fs_struct,创建一个新的fs_struct,并复制原来进程的fs_struct。 - 对于线程来说,由于设置了
CLONE_FS标识位变成将原来的fs_struct的用户数加一,并不会拷贝文件系统结构。
- 对于进程来说,这些信息用一个结构
1 | static int copy_fs(unsigned long clone_flags, struct task_struct *tsk) |
- 初始化信号相关变量
- 整个进程里的所有线程共享一个
shared_pending,这也是一个信号列表,是发给整个进程的,哪个线程处理都一样。由此我们可以做到发给进程的信号虽然可以被一个线程处理,但是影响范围应该是整个进程的。例如,kill 一个进程,则所有线程都要被干掉。如果一个信号是发给一个线程的pthread_kill,则应该只有线程能够收到。 copy_sighand- 对于进程来说,会分配一个新的
sighand_struct。这里最主要的是维护信号处理函数,在copy_sighand里面会调用memcpy,将信号处理函数sighand->action从父进程复制到子进程。 - 对于线程来说,由于设计了
CLONE_SIGHAND标记位,会对引用计数加一并退出,没有分配新的信号变量。
- 对于进程来说,会分配一个新的
1 | static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk) |
init_sigpending和copy_signal用于初始化信号结构体,并且复制用于维护发给这个进程的信号的数据结构。copy_signal函数会分配一个新的signal_struct,并进行初始化。对于线程来说也是直接退出并未复制。
1 | static int copy_signal(unsigned long clone_flags, struct task_struct *tsk) |
复制进程内存空间
- 进程都有自己的内存空间,用
mm_struct结构来表示。copy_mm()函数中调用dup_mm(),分配一个新的mm_struct结构,调用memcpy复制这个结构。dup_mmap()用于复制内存空间中内存映射的部分。前面讲系统调用的时候,我们说过,mmap可以分配大块的内存,其实mmap也可以将一个文件映射到内存中,方便可以像读写内存一样读写文件,这个在内存管理那节我们讲。 - 线程不会复制内存空间,因此因为
CLONE_VM标识位而直接指向了原来的mm_struct。
- 进程都有自己的内存空间,用
1 | static int copy_mm(unsigned long clone_flags, struct task_struct *tsk) |
- 分配
pid,设置tid,group_leader,并且建立任务之间的亲缘关系。
group_leader:进程的话group_leader就是它自己,和旧进程分开。线程的话则设置为当前进程的group_leader。tgid: 对进程来说是自己的pid,对线程来说是当前进程的pidreal_parent: 对进程来说即当前进程,对线程来说则是当前进程的real_parent
1 | static __latent_entropy struct task_struct *copy_process(......) { |
4.2 新进程的唤醒
_do_fork 做的第二件大事是通过调用 wake_up_new_task()唤醒进程。
1 | void wake_up_new_task(struct task_struct *p) |
首先,我们需要将进程的状态设置为 TASK_RUNNING。activate_task() 函数中会调用 enqueue_task()。
1 | void activate_task(struct rq *rq, struct task_struct *p, int flags) |
如果是 CFS 的调度类,则执行相应的 enqueue_task_fair()。在 enqueue_task_fair() 中取出的队列就是 cfs_rq,然后调用 enqueue_entity()。在 enqueue_entity() 函数里面,会调用 update_curr(),更新运行的统计量,然后调用 __enqueue_entity,将 sched_entity 加入到红黑树里面,然后将 se->on_rq = 1 设置在队列上。回到 enqueue_task_fair 后,将这个队列上运行的进程数目加一。然后,wake_up_new_task 会调用 check_preempt_curr,看是否能够抢占当前进程。
1 | static void |
在 check_preempt_curr 中,会调用相应的调度类的 rq->curr->sched_class->check_preempt_curr(rq, p, flags)。对于CFS调度类来讲,调用的是 check_preempt_wakeup。在 check_preempt_wakeup函数中,前面调用 task_fork_fair的时候,设置 sysctl_sched_child_runs_first 了,已经将当前父进程的 TIF_NEED_RESCHED 设置了,则直接返回。否则,check_preempt_wakeup 还是会调用 update_curr 更新一次统计量,然后 wakeup_preempt_entity 将父进程和子进程 PK 一次,看是不是要抢占,如果要则调用 resched_curr 标记父进程为 TIF_NEED_RESCHED。如果新创建的进程应该抢占父进程,在什么时间抢占呢?别忘了 fork 是一个系统调用,从系统调用返回的时候,是抢占的一个好时机,如果父进程判断自己已经被设置为 TIF_NEED_RESCHED,就让子进程先跑,抢占自己。
1 | static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags) |
至此,我们就完成了任务的整个创建过程,并根据情况唤醒任务开始执行。
五. 总结
本文十分之长,因为内容极多,源码复杂,本来想拆分为两篇文章,但是又因为过于紧密的联系因此合在了一起。本文介绍了进程的创建和线程的创建,而多进程的派生因为使用和线程内核态创建一样的函数因此放在了一起变对比边说明。由此,进程、线程的结构体以及创建过程就全部分析完了,下文将继续分析进程、线程的调度。
源码资料
[1] kernel/fork.c
[2] glibc/nptl/pthread_create.c
参考文献
[1] wiki
[3] woboq
[3] Linux-insides
[4] 深入理解Linux内核
[5] Linux内核设计的艺术
[6] 极客时间 趣谈Linux操作系统

