一. 简介
本文将分析网络协议栈发包的整个流程,根据顺序我们将依次介绍套接字文件系统、传输层、网络层、数据链路层、硬件设备层的相关发包处理流程,内容较多较复杂,主要掌握整个流程即可。
二. 套接字文件系统
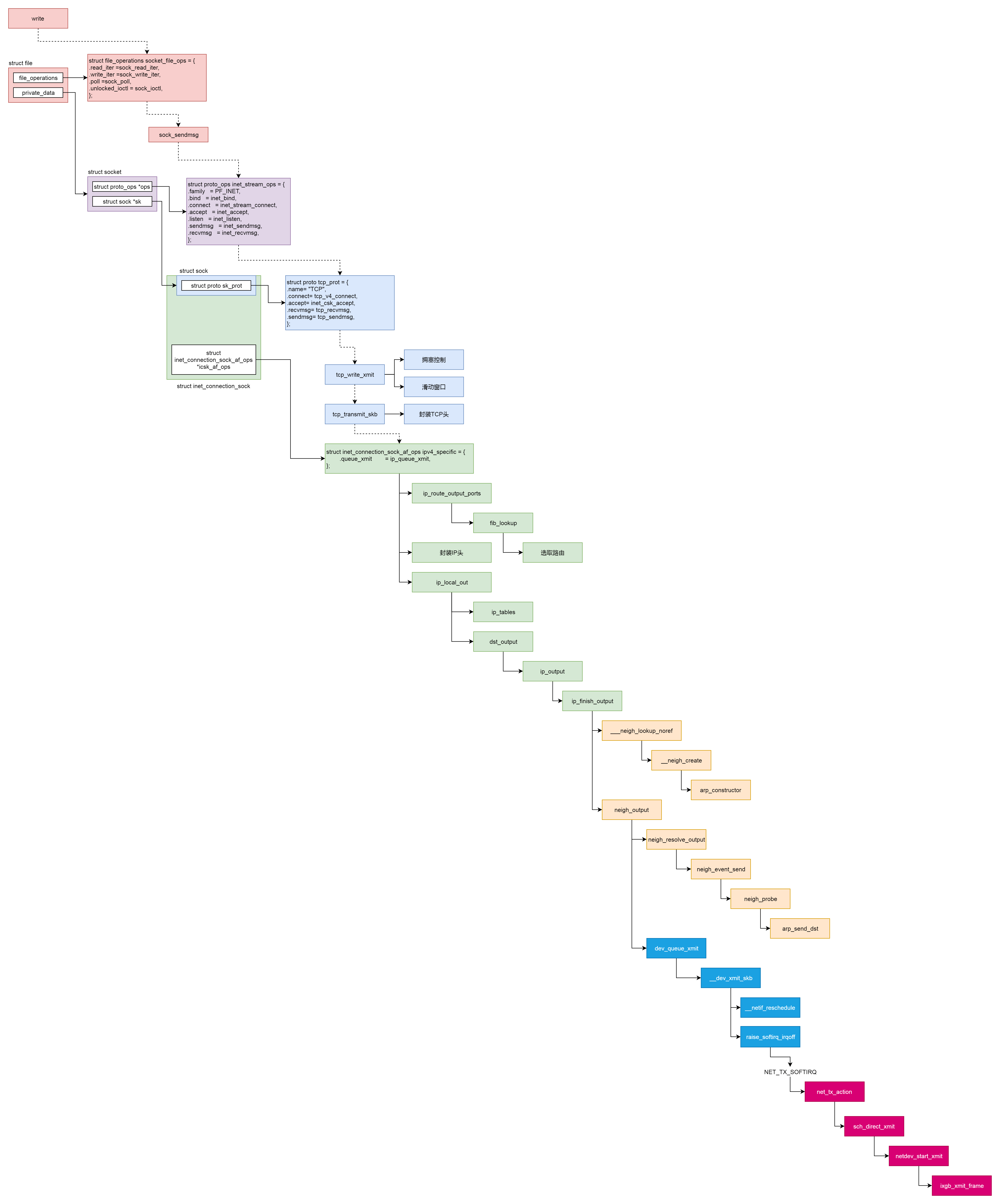
在前文中已经介绍了套接字socket和文件描述符fd以及对应的文件file的关系。在用户态使用网络编程的时候,我们可以采用write()和read()的方式通过文件描述符写入。套接字文件系统的操作定义如下,读对应的是sock_read_iter(),写对应的是sock_read_iter()
1 | static const struct file_operations socket_file_ops = { |
sock_write_iter()首先从文件file中取的对应的套接字sock,接着调用sock_sendmsg()发送消息。sock_sendmsg()则调用定义在inet_stream_ops中的sendmsg()函数,即inet_sendmsg()。inet_sendmsg()会获取协议对应的sendmsg()函数并调用,对于TCP来说则是tcp_sendmsg()。
1 | static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from) |
三. TCP层
通过前文分析我们知道sk_buff存放了所有需要发送的数据包,因此来自于用户态的msg也需要填写至其中。tcp_sendmsg()需要首先要分配空闲的sk_buff并拷贝msg,接着需要将该消息发送出去。其中消息的拷贝考虑到可能较长需要分片,因此会循环分配,循环主要逻辑为:
- 调用
tcp_send_mss()计算MSS大小, - 调用
tcp_write_queue_tail()获取sk_buff链表最后一项,因为可能还有剩余空间。 copy小于0说明当前sk_buff并无可用空间,因此需要调用sk_stream_alloc_skb()重新分配sk_buff,然后调用skb_entail()将新分配的sk_buff放到队列尾部,copy赋值为size_goal- 由于
sk_buff存在连续数据区域和离散的数据区skb_shared_info,因此需要分别讨论。调用skb_add_data_nocache()可以 将数据拷贝到连续的数据区域。调用skb_copy_to_page_nocache()则将数据拷贝到 structskb_shared_info结构指向的不需要连续的页面区域。 - 根据上面得到的
sk_buff进行发送。如果累积了较多的数据包,则调用__tcp_push_pending_frames()发送,如果是第一个包则调用tcp_push_one()。二者最后均会调用tcp_write_xmit发送。
1 | int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) |
tcp_write_xmit()的核心部分为一个循环,每次调用tcp_send_head()获取头部sk_buff,若已经读完则退出循环。循环内逻辑为:
- 调用
tcp_init_tso_segs()进行TSO(TCP Segmentation Offload)相关工作。当需要发送较大的网络包的时候,我们可以选择在协议栈中进行分段,也可以选择延迟到硬件网卡去进行自动分段以降低CPU负载。 - 调用
tcp_cwnd_test()检查现在拥塞窗口是否允许发包,如果允许,返回可以发送多少个sk_buff。 - 调用
tcp_snd_wnd_test()检测当前第一个sk_buff的序列号是否满足要求:sk_buff中的end_seq和tcp_wnd_end(tp)之间的关系,也即这个sk_buff是否在滑动窗口的允许范围之内。 tso_segs为1可能是nagle协议导致,需要进行判断。其次需要判断TSO是否延迟到硬件网卡进行。- 调用
tcp_mss_split_point()判断是否会因为超出mss而分段,还会判断另一个条件,就是是否在滑动窗口的运行范围之内,如果小于窗口的大小,也需要分段,也即需要调用tso_fragment()。 - 调用
tcp_small_queue_check()检查是否需要采取小队列:TCP小队列对每个TCP数据流中,能够同时参与排队的字节数做出了限制,这个限制是通过net.ipv4.tcp_limit_output_bytes内核选项实现的。当TCP发送的数据超过这个限制时,多余的数据会被放入另外一个队列中,再通过tastlet机制择机发送。由于该限制的存在,TCP通过一味增大缓冲区的方式是无法发出更多的数据包的。 - 调用
tcp_transmit_skb()完成sk_buff的真正发送工作。
1 | static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, |
tcp_transmit_skb()函数主要完成TCP头部的填充。这里面有源端口,设置为 inet_sport,有目标端口,设置为 inet_dport;有序列号,设置为 tcb->seq;有确认序列号,设置为 tp->rcv_nxt。所有的 flags 设置为 tcb->tcp_flags。设置选项为 opts。设置窗口大小为 tp->rcv_wnd。完成之后调用 icsk_af_ops 的 queue_xmit() 方法,icsk_af_ops 指向 ipv4_specific,也即调用的是 ip_queue_xmit() 函数,进入IP层。
1 |
|
四. IP层
ip_queue_xmit()实际调用__ip_queue_xmit(),其逻辑为
- 调用
ip_route_output_ports()选取路由,也即我要发送这个包应该从哪个网卡出去 - 填充IP层头部。在这里面,服务类型设置为
tos,标识位里面设置是否允许分片frag_off。如果不允许,而遇到MTU太小过不去的情况,就发送ICMP报错。TTL是这个包的存活时间,为了防止一个IP包迷路以后一直存活下去,每经过一个路由器TTL都减一,减为零则“死去”。设置protocol,指的是更上层的协议,这里是TCP。源地址和目标地址由ip_copy_addrs()设置。最后设置options。 - 调用
ip_local_out()发送IP包
1 | /* Note: skb->sk can be different from sk, in case of tunnels */ |
下面看看选取路由的部分,其调用链为ip_route_output_ports()->ip_route_output_flow()->__ip_route_output_key()->ip_route_output_key_hash()->ip_route_output_key_hash_rcu()。最终会先调用fib_lookup()进行路由查找,接着会调用__mkroute_output()创建rtable结构体实例rth表示找到的路由表项并返回。
1 | struct rtable *ip_route_output_key_hash_rcu(struct net *net, struct flowi4 *fl4, struct fib_result *res, const struct sk_buff *skb) |
fib_lookup()首先调用fib_get_table()获取对应的路由表,接着调用fib_table_lookup()在路由表中找寻对应的路由。由于IP本身是点分十进制的数,所以在路由表中实际采取的是Trie树结构体进行存储以便于查找匹配。通过Trie树可以完美契合IP地址的分类方式,迅速找到符合的路由。
1 | static inline int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res, unsigned int flags) |
ip_local_out()首先调用__ip_local_out(),实际调用nf_hook(),nf_hook()是大名鼎鼎的netfilter在IP层注册的钩子函数的位置。接着会调用dst_output()进行数据发送。
1 | int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) |
关于Netfilter,我打算在后面单独开一篇文章详细介绍,因为的确很复杂而且具有研究价值。这里先简单介绍一下。下图是Netfilter和对应的iptables, ip_tables的关系示意图。由此可见,我们可以在用户态通过iptables命令操作,而实际上则是在IP层通过五个挂载点实现控制。
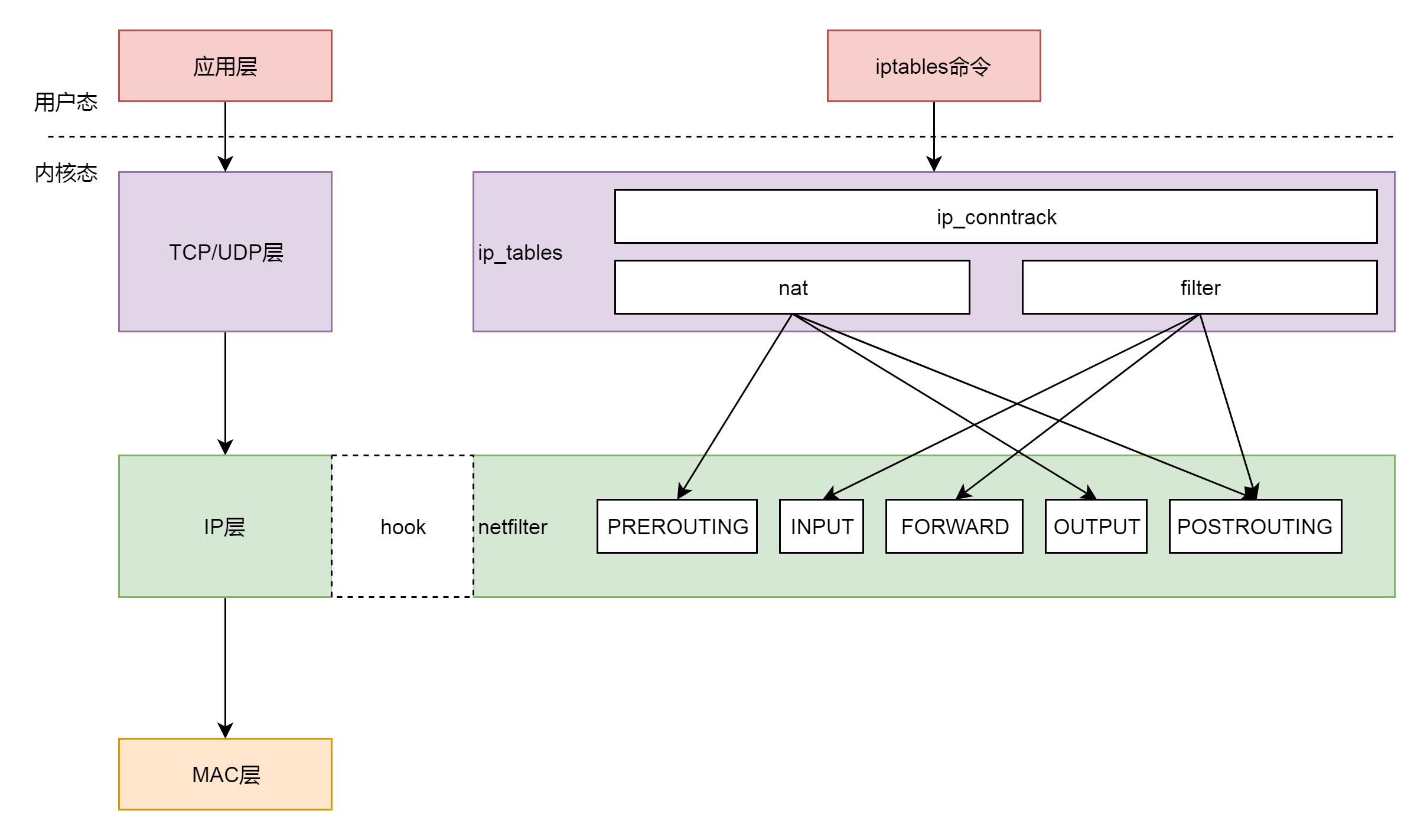
五个挂载点实际工作位置如下图所示
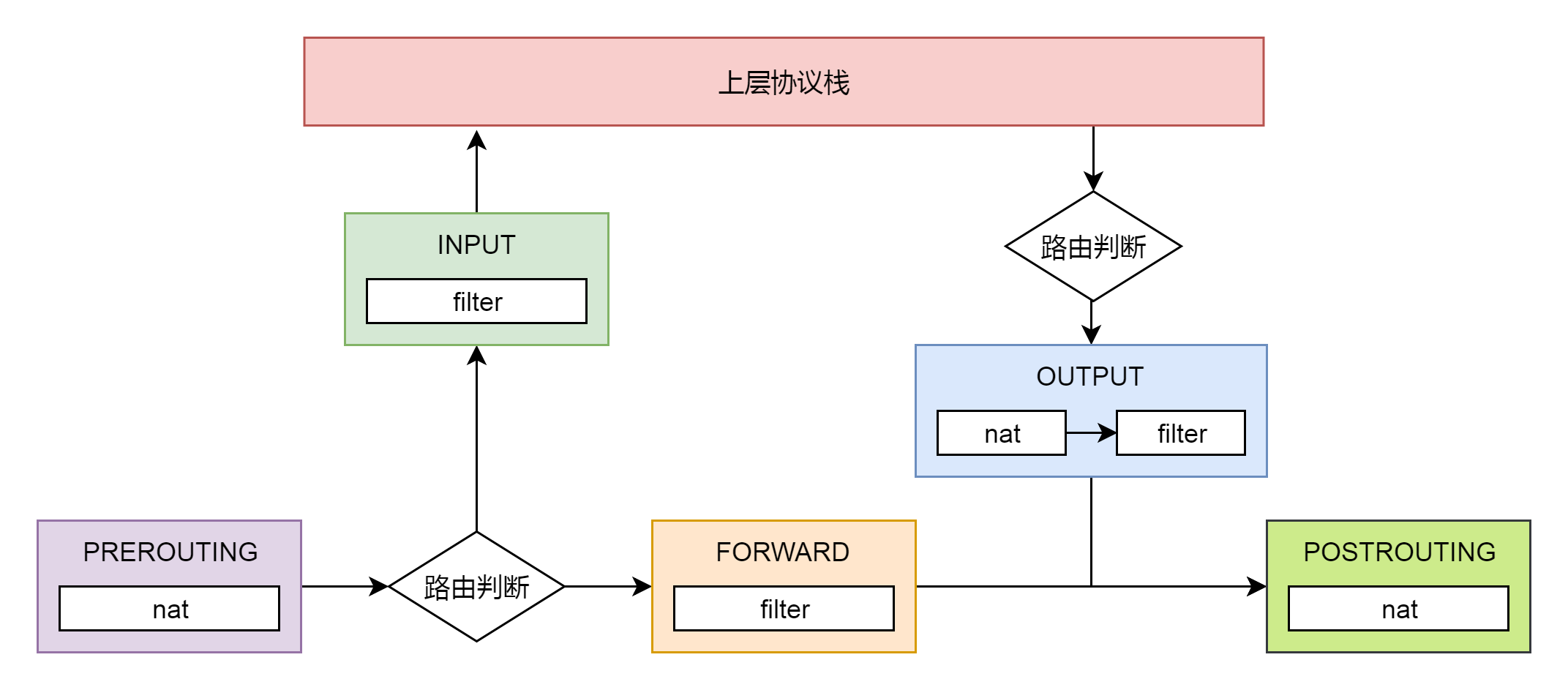
filter 表处理过滤功能,主要包含以下三个链。
- INPUT 链:过滤所有目标地址是本机的数据包
- FORWARD 链:过滤所有路过本机的数据包
- OUTPUT 链:过滤所有由本机产生的数据包
nat 表主要处理网络地址转换,可以进行 SNAT(改变源地址)、DNAT(改变目标地址),包含以下三个链。
- PREROUTING 链:可以在数据包到达时改变目标地址
- OUTPUT 链:可以改变本地产生的数据包的目标地址
- POSTROUTING 链:在数据包离开时改变数据包的源地址
在这里,网络包马上就要发出去了,因而是 NF_INET_LOCAL_OUT,也即 ouput 链,如果用户曾经在 iptables 里面写过某些规则,就会在 nf_hook 这个函数里面起作用。
dst_output()实际调用的就是 struct rtable 成员 dst 的 ouput() 函数。在 rt_dst_alloc() 中,我们可以看到,output() 函数指向的是 ip_output()。
1 | /* Output packet to network from transport. */ |
在 ip_output 里面我们又看到了熟悉的 NF_HOOK。这一次是 NF_INET_POST_ROUTING,也即 POSTROUTING 链,处理完之后调用 ip_finish_output()进入MAC层。
五. MAC层
ip_finish_output()实际调用ip_finish_output2(),其主要逻辑为:
- 找到
struct rtable路由表里面的下一跳,下一跳一定和本机在同一个局域网中,可以通过二层进行通信,因而通过__ipv4_neigh_lookup_noref(),查找如何通过二层访问下一跳。 - 如果没有找到,则调用
__neigh_create()进行创建 - 调用
neigh_output()发送网络报
1 | static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb) |
__ipv4_neigh_lookup_noref()实际调用___neigh_lookup_noref()从本地的 ARP 表中查找下一跳的 MAC 地址,具体做法为获取下一跳哈希值,并在哈希表中找取对应的节点neighbour
1 | static inline struct neighbour *__ipv4_neigh_lookup_noref(struct net_device *dev, u32 key) |
其中ARP表neigh_table *arp_tbl定义为
1 | struct neigh_table arp_tbl = { |
__neigh_create()逻辑为
- 调用
neigh_alloc()创建neighbour结构体用于维护MAC地址和ARP相关的信息 - 调用了
arp_tbl的constructor函数,也即调用了arp_constructor,在这里面定义了 ARP 的操作arp_hh_ops - 将创建的
struct neighbour结构放入一个哈希表,这是一个数组加链表的链式哈希表,先计算出哈希值hash_val得到相应的链表,然后循环这个链表找到对应的项,如果找不到就在最后插入一项
1 | struct neighbour *__neigh_create(struct neigh_table *tbl, const void *pkey, |
在 neigh_alloc() 中,比较重要的有两个成员,一个是 arp_queue,上层想通过 ARP 获取 MAC 地址的任务都放在这个队列里面。另一个是 timer 定时器,设置成过一段时间就调用 neigh_timer_handler()来处理这些 ARP 任务。
1 | static struct neighbour *neigh_alloc(struct neigh_table *tbl, struct net_device *dev) |
完成了__neigh_create()后,ip_finish_output2()就会调用neigh_output()发送网络包。按照上面对于 struct neighbour 的操作函数 arp_hh_ops 的定义,output 调用的是 neigh_resolve_output()。 neigh_resolve_output() 逻辑为
- 调用
neigh_event_send()触发一个事件,看能否激活ARP - 当
ARP发送完毕,就可以调用dev_queue_xmit()发送二层网络包了。
1 | int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb) |
在 __neigh_event_send() 中,激活 ARP 分两种情况,第一种情况是马上激活,也即 immediate_probe()。另一种情况是延迟激活则仅仅设置一个 timer。然后将 ARP 包放在 arp_queue() 上。如果马上激活,就直接调用 neigh_probe();如果延迟激活,则定时器到了就会触发 neigh_timer_handler(),在这里面还是会调用 neigh_probe()。
1 | static inline int neigh_event_send(struct neighbour *neigh, struct sk_buff *skb) |
neigh_probe()会从 arp_queue 中拿出 ARP 包来,然后调用 struct neighbour 的 solicit 操作,即arp_solicit(),最终调用arp_send_dst()创建并发送ARP包,并将结果放在struct dst_entry中。
1 | static void neigh_probe(struct neighbour *neigh) |
当 ARP 发送完毕,就可以调用 dev_queue_xmit() 发送二层网络包了,实际调用__dev_queue_xmit()。
1 | /** |
每个块设备都有队列,用于将内核的数据放到队列里面,然后设备驱动从队列里面取出后,将数据根据具体设备的特性发送给设备。网络设备也是类似的,对于发送来说,有一个发送队列 struct netdev_queue *txq。这里还有另一个变量叫做 struct Qdisc,该队列就是大名鼎鼎的流控队列了。经过流控许可发送,最终就会调用__dev_xmit_skb()进行发送。
__dev_xmit_skb() 会将请求放入队列,然后调用 __qdisc_run() 处理队列中的数据。qdisc_restart 用于数据的发送。qdisc 的另一个功能是用于控制网络包的发送速度,因而如果超过速度,就需要重新调度,则会调用 __netif_schedule()。
1 | static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q, |
__netif_schedule() 会调用 __netif_reschedule()发起一个软中断 NET_TX_SOFTIRQ。设备驱动程序处理中断分两个过程,一个是屏蔽中断的关键处理逻辑,一个是延迟处理逻辑。工作队列是延迟处理逻辑的处理方案,软中断也是一种方案。在系统初始化的时候,我们会定义软中断的处理函数。例如,NET_TX_SOFTIRQ 的处理函数是 net_tx_action(),用于发送网络包。还有一个 NET_RX_SOFTIRQ 的处理函数是 net_rx_action(),用于接收网络包。
1 | static void __netif_reschedule(struct Qdisc *q) |
net_tx_action() 调用了 qdisc_run(),最终和__dev_xmit_skb()一样调用 __qdisc_run(),通过qdisc_restart()完成发包。
1 | static __latent_entropy void net_tx_action(struct softirq_action *h) |
qdisc_restart() 将网络包从 Qdisc 的队列中拿下来,然后调用 sch_direct_xmit() 进行发送。
1 |
|
sch_direct_xmit() 调用 dev_hard_start_xmit() 进行发送,如果发送不成功,会返回 NETDEV_TX_BUSY。这说明网络卡很忙,于是就调用 dev_requeue_skb(),重新放入队列。
1 | int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, |
dev_hard_start_xmit() 通过一个 while 循环每次在队列中取出一个 sk_buff,调用 xmit_one() 发送。接下来的调用链为:xmit_one()->netdev_start_xmit()->__netdev_start_xmit()。
1 | struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev, |
这个时候,已经到了设备驱动层了。我们能看到,drivers/net/ethernet/intel/ixgbe/ixgbe_main.c里面有对于这个网卡的操作的定义(英特尔网卡有多种不同的型号,对应于intel目录下不同的驱动,这里我们仅挑选其中的一种来做分析)。在这里面,我们可以找到对于 ndo_start_xmit() 的定义,实际会调用 ixgb_xmit_frame()。在 ixgb_xmit_frame() 中,我们会得到这个网卡对应的适配器,然后将其放入硬件网卡的队列中。至此,整个发送才算结束。
1 | static const struct net_device_ops ixgbe_netdev_ops = { |
总结
整个网络协议栈的发送流程很长,中间也有不少关键步骤值得注意,值得仔细研究。
源码资料
[1] socket_file_ops
[2] tcp_sendmsg()
[3] tcp_write_xmit()
[4] ip_queue_xmit()
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统
[8] 深入理解Linux网络技术内幕

