一. 简介
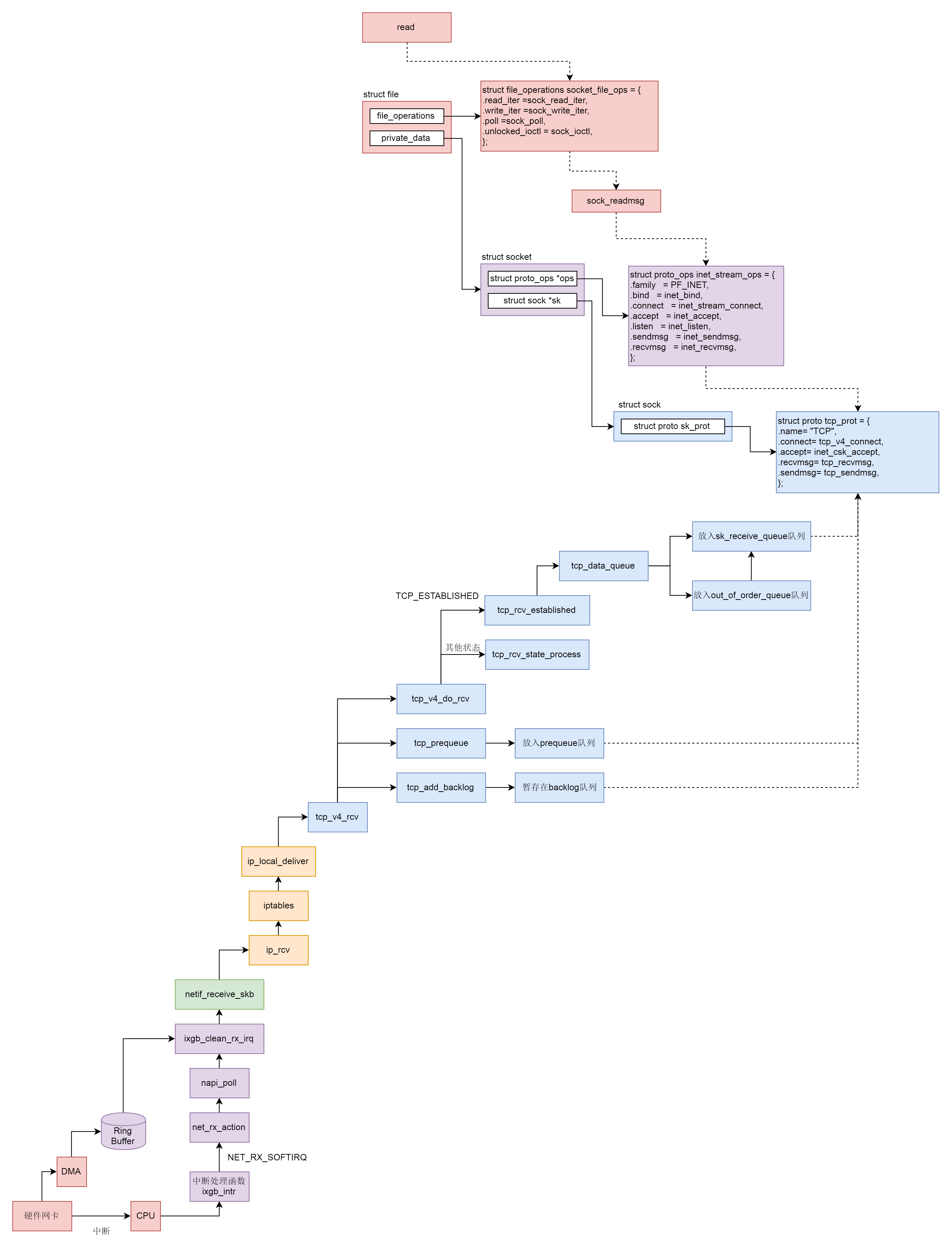
本文将分析网络协议栈收包的整个流程,收包和发包是刚好相反的过程。根据顺序我们将依次介绍硬件设备驱动层、数据链路层、网络层、传输层、套接字文件系统的相关发包处理流程,内容较多较复杂,主要掌握整个流程即可。
二. 网卡驱动层
网卡作为一个硬件,接收到网络包后靠中断来通知操作系统。但是这里有个问题:网络包的到来往往是很难预期的。网络吞吐量比较大的时候,网络包的到达会十分频繁。这个时候,如果非常频繁地去触发中断,会造成频繁的上下文切换,带来极大的开销。因此硬件处理厂商设计了一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询 poll 网卡的方式主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断,再轮询 poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式我们称为 NAPI。
本文以 Intel(R) PRO/10GbE 网卡驱动为例,在网卡驱动程序初始化的时候,我们会调用 ixgb_init_module()注册一个驱动 ixgb_driver,并且调用它的 probe 函数 ixgb_probe()。
1 | static struct pci_driver ixgb_driver = { |
ixgb_probe() 会创建一个 struct net_device 表示这个网络设备,并且调用 netif_napi_add() 函数为这个网络设备注册一个轮询 poll 函数 ixgb_clean(),将来一旦出现网络包的时候,就通过该函数来轮询。
1 | static int |
网卡被激活的时候会调用函数 ixgb_open()->ixgb_up(),在这里面注册一个硬件的中断处理函数。
1 | intixgb_up(struct ixgb_adapter *adapter) |
如果一个网络包到来,触发了硬件中断,就会调用 ixgb_intr(),这里面会调用 __napi_schedule()。
1 | static irqreturn_t ixgb_intr(int irq, void *data) |
__napi_schedule() 处于中断处理的关键部分,在被调用的时候,中断是暂时关闭的。处理网络包是个复杂的过程,需要到中断处理的延迟处理部分执行,所以 ____napi_schedule() 将当前设备放到 struct softnet_data 结构的 poll_list 里面,说明在延迟处理部分可以接着处理这个 poll_list 里面的网络设备。然后 ____napi_schedule() 触发一个软中断 NET_RX_SOFTIRQ,通过软中断触发中断处理的延迟处理部分,也是常用的手段。
1 | /** |
软中断 NET_RX_SOFTIRQ 对应的中断处理函数是 net_rx_action(),其逻辑为
- 调用
this_cpu_ptr(),得到struct softnet_data结构,这个结构在发送的时候我们也遇到过。当时它的output_queue用于网络包的发送,这里的poll_list用于网络包的接收。 - 进入循环,从
poll_list里面取出有网络包到达的设备,然后调用napi_poll()来轮询这些设备,napi_poll()会调用最初设备初始化的时候注册的poll函数,对于ixgb_driver对应的函数是ixgb_clean()。
1 | static __latent_entropy void net_rx_action(struct softirq_action *h) |
ixgb_clean() 实际调用ixgb_clean_rx_irq()。在网络设备的驱动层,有一个用于接收网络包的 rx_ring。它是一个环,从网卡硬件接收的包会放在这个环里面。这个环里面的 buffer_info[]是一个数组,存放的是网络包的内容。i 和 j 是这个数组的下标,在 ixgb_clean_rx_irq() 里面的 while 循环中,依次处理环里面的数据。在这里面,我们看到了 i 和 j 加一之后,如果超过了数组的大小,就跳回下标 0,就说明这是一个环。ixgb_check_copybreak() 函数将 buffer_info 里面的内容拷贝到 struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用 netif_receive_skb()进入MAC层继续进行收包的解析处理。
1 | static int ixgb_clean(struct napi_struct *napi, int budget) |
三. MAC层
从 netif_receive_skb() 函数开始,我们就进入了内核的网络协议栈。接下来的调用链为:netif_receive_skb()->netif_receive_skb_internal()->__netif_receive_skb()->__netif_receive_skb_core()。在 __netif_receive_skb_core() 中,我们先是处理了二层的一些逻辑,如对于 VLAN 的处理,如果不是则调用deliver_ptype_list_skb() 在一个协议列表中逐个匹配在网络包 struct sk_buff 里面定义的 skb->protocol,该变量表示三层使用的协议类型。
1 | static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) |
无论是VLAN还是普通的包,最后的发送均会调用deliver_skb(),该函数会调用协议定义好的函数进行网络层解析。对于IP协议即为ip_rcv()。
1 | static inline int deliver_skb(struct sk_buff *skb, |
四. 网络层
在ip_rcv()中,我们又看到了熟悉的Netfilter,这次对应的是PREROUTING状态,执行完定义的钩子函数后,会继续执行ip_rcv_finish()。
1 | int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, |
ip_rcv_finish() 首先调用ip_rcv_finish_core(),该函数会先检测是否为广播、组播,如果不是则得到网络包对应的路由表,然后调用 dst_input(),在 dst_input() 中,调用的是 struct rtable 的成员的 dst 的 input() 函数。在 rt_dst_alloc() 中,我们可以看到input 函数指向的是 ip_local_deliver()。
1 | static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) |
进入ip_local_deliver()意味着从PREROUTING确认进入本机处理,所以进入了状态INPUT,如果 IP 层进行了分段,则进行重新的组合。接下来就是我们熟悉的 NF_HOOK。在经过 iptables 规则处理完毕后,会调用 ip_local_deliver_finish()。
1 | int ip_local_deliver(struct sk_buff *skb) |
ip_local_deliver_finish()首先调用__skb_pull()从sk_buff中取下一个,接着调用ip_protocol_deliver_rcu(),该函数会从inet_protos[protocol]中找寻对应的处理函数进一步对收到的数据包进行解析。对应TCP的是tcp_v4_rcv(),UDP则是udp_rcv()。
1 | static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb) |
五. 传输层
在 tcp_v4_rcv() 中,首先会获取 TCP 的头部,接着就开始处理 TCP 层的事情。因为 TCP 层是分状态的,状态被维护在数据结构 struct sock 里面,因而要根据 IP 地址以及 TCP 头里面的内容,在 tcp_hashinfo 中找到这个包对应的 struct sock,从而得到这个包对应的连接的状态。接下来就根据不同的状态做不同的处理。如在前文三次握手的分析中已经剖析了TCP_NEW_SYN_RECV后续的逻辑。对于正常通信包,则会涉及到三条队列的操作。
1 | int tcp_v4_rcv(struct sk_buff *skb) |
网络包接收过程中常见的三个队列为
- backlog 队列:软中断过程中的数据包处理队列
- prequeue 队列:用户态进程读队列
- sk_receive_queue 队列:内核态数据包缓存队列
存在三个队列的原因是运行至tcp_v4_rcv()时,依然处于软中断的处理逻辑里,所以必然会占用这个软中断。如果用户态使用了系统调用read()读取数据包,则放入prequeue队列等待读取,如果暂时没有读取请求,则放入内核态的缓存队列sk_receive_queue中等候用户态请求。
tcp_v4_rcv()调用sock_owned_by_user()判断该包现在是否正在被用户态进行读操作,如果没有则调用tcp_add_backlog()暂存在 backlog 队列中,并且抓紧离开软中断的处理过程,如果是则调用 tcp_prequeue(),将数据包放入 prequeue 队列并且离开软中断的处理过程。在这个函数里面,会对 sysctl_tcp_low_latency 进行判断,也即是不是要低时延地处理网络包。如果把 sysctl_tcp_low_latency 设置为 0,那就要放在 prequeue 队列中暂存,这样不用等待网络包处理完毕,就可以离开软中断的处理过程,但是会造成比较长的时延。如果把 sysctl_tcp_low_latency 设置为 1,则调用 tcp_v4_do_rcv()立即处理。
特别注意:在2017年的一个patch中,有大佬提出取消prequeue队列以顺应新的TCP需求。但是我们这里依然以三条队列进行分析,实际上代码中较新的版本已经没有了tcp_prequeue()函数。之所以取消prequeue,是因为在大多使用事件驱动(epoll)的当下,已经很少有阻塞在recvfrom()或者read()的服务端代码了。下面分析中会加上prequeue相关功能,但是实际代码中不一定有。
在 tcp_v4_do_rcv() 中会分两种情况处理,一种情况是连接已经建立,处于 TCP_ESTABLISHED 状态,调用 tcp_rcv_established()。另一种情况,就是未建立连接的状态,调用 tcp_rcv_state_process()。关于tcp_rcv_state_process()在三次握手中已分析过了,这里重点看tcp_rcv_established()。该函数会调用 tcp_data_queue(),将数据包放入 sk_receive_queue 队列进行处理。
1 | void tcp_rcv_established(struct sock *sk, struct sk_buff *skb) |
在 tcp_data_queue() 中,对于收到的网络包,我们要分情况进行处理。
- 第一种情况,
seq == tp->rcv_nxt,说明来的网络包正是我服务端期望的下一个网络包。- 调用
sock_owned_by_user()判断用户进程是否正在等待读取,如果是则直接调用skb_copy_datagram_msg(),将网络包拷贝给用户进程就可以了。如果用户进程没有正在等待读取,或者因为内存原因没有能够拷贝成功,tcp_queue_rcv()里面还是将网络包放入sk_receive_queue队列。 - 调用
tcp_rcv_nxt_update()将tp->rcv_nxt设置为end_seq,也即当前的网络包接收成功后,更新下一个期待的网络包 - 判断一下另一个队列
out_of_order_queue,即乱序队列的情况,看看乱序队列里面的包会不会因为这个新的网络包的到来,也能放入到sk_receive_queue队列中。
- 调用
- 第二种情况,
end_seq小于rcv_nxt,也即服务端期望网络包 5。但是,来了一个网络包 3,怎样才会出现这种情况呢?肯定是服务端早就收到了网络包 3,但是 ACK 没有到达客户端,中途丢了,那客户端就认为网络包 3 没有发送成功,于是又发送了一遍,这种情况下,要赶紧给客户端再发送一次 ACK,表示早就收到了。 - 第三种情况,
seq大于rcv_nxt + tcp_receive_window。这说明客户端发送得太猛了。本来seq肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。这种情况下,服务端不能再接收数据包了,只能发送 ACK 了,在 ACK 中会将接收窗口为 0 的情况告知客户端,客户端就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在 ACK 里面再次告诉客户端,又有窗口了,又能发送数据包了。 - 第四种情况,
seq小于rcv_nxt,但是end_seq大于rcv_nxt,这说明从seq到rcv_nxt这部分网络包原来的 ACK 客户端没有收到,所以重新发送了一次,从rcv_nxt到end_seq是新发送的,可以放入sk_receive_queue队列。 - 第五种情况,是正好在接收窗口内但是不是期望接收的下一个包,则说明发生了乱序,调用
tcp_data_queue_ofo()加入乱序队列中。
1 | static void tcp_data_queue(struct sock *sk, struct sk_buff *skb) |
六. 套接字层
当接收的网络包进入各种队列之后,接下来我们就要等待用户进程去读取它们了。读取一个 socket,就像读取一个文件一样,读取 socket 的文件描述符,通过 read 系统调用。read 系统调用对于一个文件描述符的操作,大致过程都是类似的,在文件系统那一节,我们已经详细解析过。最终它会调用到用来表示一个打开文件的结构 stuct file 指向的 file_operations 操作。
1 | static const struct file_operations socket_file_ops = { |
sock_read_iter()首先从虚拟文件系统中获取对应的文件,然后通过file获取对应的套接字sock,接着调用sock_recvmsg()读取该套接字对应的连接的数据包缓存队列。
1 | static ssize_t sock_read_iter(struct kiocb *iocb, struct iov_iter *to) |
sock_recvmsg()实际调用sock_recvmmsg_nosec(),该函数会调用套接字对应的读操作,即inet_recvmsg()。
1 | int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags) |
inet_recvmsg()会调用协议对应的读操作,即tcp_recvmsg()进行读操作。
1 | int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size, |
tcp_recvmsg()通过一个循环读取队列中的数据包,直至读完。循环内的逻辑为:
- 处理
sk_receive_queue队列:调用skb_peek_tail()获取队列中的一项,并调用skb_queue_walk()处理。如果找到了网络包,就跳到found_ok_skb这里。这里会调用skb_copy_datagram_msg()将网络包拷贝到用户进程中,然后直接进入下一层循环。 - 处理
prequeue队列(已废弃):直到sk_receive_queue队列处理完毕才到了sysctl_tcp_low_latency判断。如果不需要低时延,则会有prequeue队列。于是跳到do_prequeue这里,调用tcp_prequeue_process()进行处理。 - 处理
backlog队列:调用release_sock()完成。release_sock()会调用__release_sock(),这里面会依次处理队列中的网络包。 - 处理完所有队列后,调用
sk_wait_data(),继续等待在哪里,等待网络包的到来。
1 |
|
总结
至此网络协议栈的收发流程都已经分析完毕了。收包流程可以总结为以下过程
- 硬件网卡接收到网络包之后,通过 DMA 技术,将网络包放入 Ring Buffer;
- 硬件网卡通过中断通知 CPU 新的网络包的到来;
- 网卡驱动程序会注册中断处理函数 ixgb_intr;
- 中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断 NET_RX_SOFTIRQ 触发接下来的处理过程;
- NET_RX_SOFTIRQ 软中断处理函数
net_rx_action,net_rx_action会调用napi_poll,进而调用ixgb_clean_rx_irq,从 Ring Buffer 中读取数据到内核struct sk_buff; - 调用
netif_receive_skb进入内核网络协议栈,进行一些关于 VLAN 的二层逻辑处理后,调用ip_rcv进入三层 IP 层; - 在 IP 层,会处理
iptables规则,然后调用ip_local_deliver交给更上层 TCP 层; - 在 TCP 层调用
tcp_v4_rcv,这里面有三个队列需要处理,如果当前的Socket不是正在被读取,则放入backlog队列,如果正在被读取,不需要很实时的话,则放入prequeue队列,其他情况调用tcp_v4_do_rcv; - 在
tcp_v4_do_rcv中,如果是处于TCP_ESTABLISHED状态,调用tcp_rcv_established,其他的状态,调用tcp_rcv_state_process; - 在
tcp_rcv_established中,调用tcp_data_queue,如果序列号能够接的上,则放入sk_receive_queue队列; - 如果序列号接不上,则暂时放入
out_of_order_queue队列,等序列号能够接上的时候,再放入sk_receive_queue队列。
至此内核接收网络包的过程到此结束,接下来就是用户态读取网络包的过程,这个过程分成几个层次。
- VFS 层:
read系统调用找到struct file,根据里面的file_operations的定义,调用sock_read_iter函数。sock_read_iter函数调用sock_recvmsg函数。 - Socket 层:从
struct file里面的private_data得到struct socket,根据里面ops的定义,调用inet_recvmsg函数。 - Sock 层:从
struct socket里面的sk得到struct sock,根据里面sk_prot的定义,调用tcp_recvmsg函数。 - TCP 层:
tcp_recvmsg函数会依次读取receive_queue队列、prequeue队列和backlog队列。
源码资料
[3] ip_rcv()
[4] tcp_v4_rcv()
[5] sock_read_iter()
[6] inet_recvmsg()
[7] tcp_recvmsg()
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统
[8] 深入理解Linux网络技术内幕

