一. 前言
在前面的几篇文章中,我们大致介绍了Linux网络协议栈的基本结构体、收发流程、TCP协议设计原理等,整个网络通信其实是一个很复杂的过程。本文介绍性能测试、性能评估、性能优化等方方面面的基本内容和大致优化思路。
二. 总体性能参数和工具
对于服务器来说,首先需要一个大致的轮廓来描述其性能,这些性能参数将整个应用视为黑盒,测试其从外部看上去的性能表现,属于第一步需要掌握的数据。只有先掌握了这些数据后,后续的分析才有意义。
- 带宽:表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。带宽决定了网络的承载能力,如果网络带宽无法承受用户连接,那么则会出现致命的问题。
- 吞吐量:表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 时延:表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
PPS:Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即PPS可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。- 并发连接数:TCP的连接数数量
- 丢包率:网络丢包百分比
- 重传率:网络重传百分比
我们可以使用以下工具完成需要的性能参数
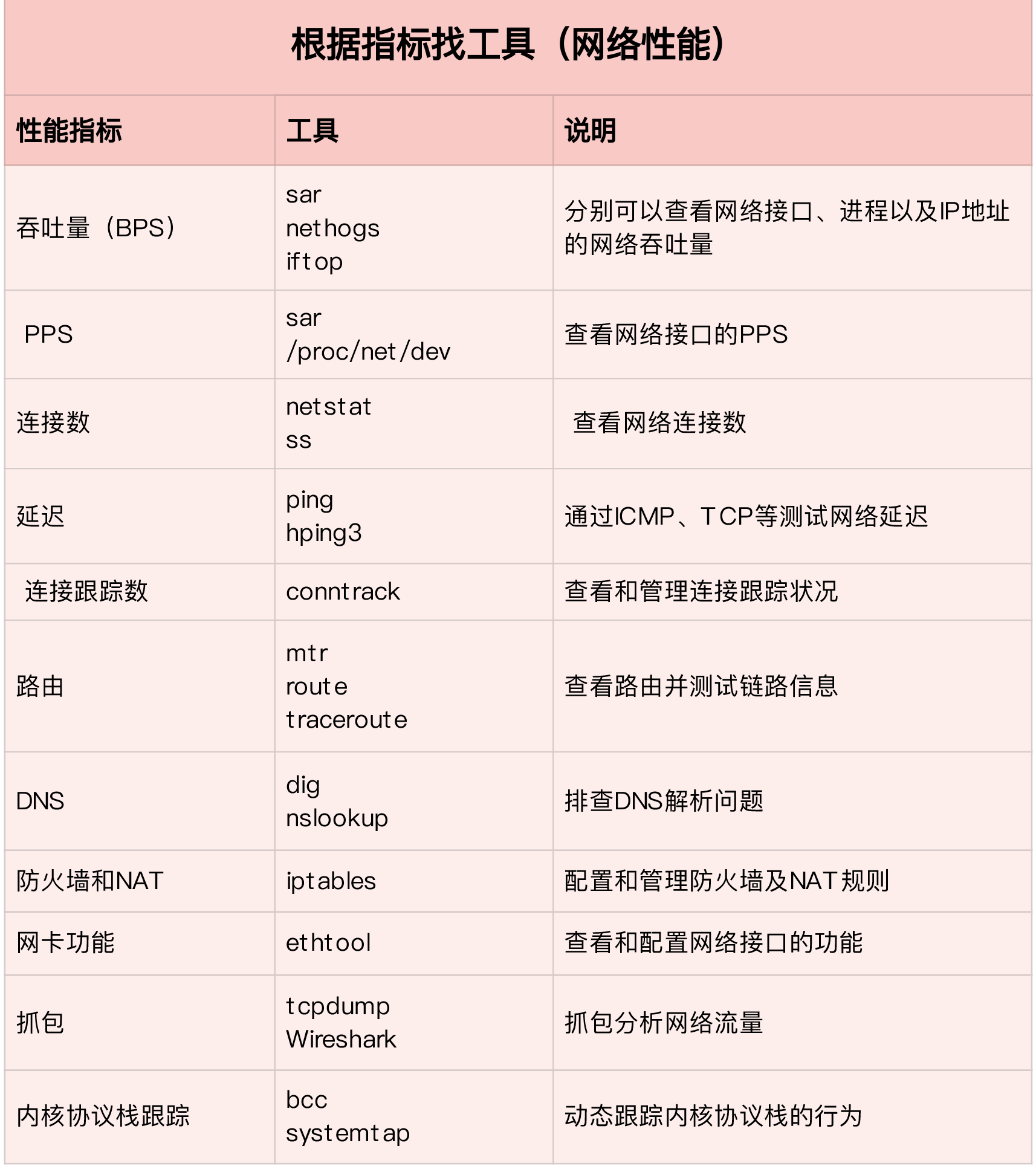
- 使用
ethtool可以查询当前带宽信息等网卡功能
1 | # 这里仅输出Speed就够用了,其他的没有太大参考价值 |
- 使用
ping查看网络联通性
1 | root@ubuntu:/home/ty# ping -c3 www.chtyty.com |
- 使用
sar -n可以查询如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等,我们这里用它来查询PPS,吞吐量和网络接口使用率。
1 | # 数字1表示每隔1秒输出一组数据 |
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth
- 注意,
sar工具不一定自带,可以通过sudo apt-get install -y sysstat安装
- 使用
ifconfig/ip指令获取当前基础信息状态:网络接口的状态标志、MTU 大小、IP、子网、MAC 地址以及网络包收发的统计信息。
1 | root@ubuntu:/home/ty# ifconfig ens33 |
- 网络接口的状态标志中,
ifconfig输出中的RUNNING或ip输出中的LOWER_UP都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。 - MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了
VXLAN等叠加网络),你可能需要调大或者调小MTU的数值。 - 网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的
errors、dropped、overruns、carrier以及collisions等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:errors表示发生错误的数据包数,比如校验错误、帧同步错误等;dropped表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;overruns表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;carrier表示发生carrirer错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;collisions表示碰撞数据包数。
- 使用
netstat/ss -ntlp指令获取当前套接字状态:全连接队列长度、最大长度、收发缓冲区用量
1 | # head -n 5 表示只显示前面5行 |
- 当套接字处于连接状态(
Established)时,Recv-Q表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。 - 当套接字处于监听状态(
Listening)时,Recv-Q表示全连接队列的长度。而 Send-Q 表示全连接队列的最大长度。
- 使用
netstat/ss -s指令获取当前连接状态:主动连接、被动连接、失败重试、发送和接收的分段数量、TCP扩展性能等各种信息。ss只显示已经连接、关闭、孤儿套接字等简要统计,而netstat则提供的是更详细的网络协议栈信息。
1 | root@ubuntu:/home/ty# netstat -st |
三.协议逐层优化
除了针对整个服务端性能的“黑盒”测试评估外,当发现性能有问题的时候,我们还需要针对性的逐层分析性能,从而找到问题的根源。
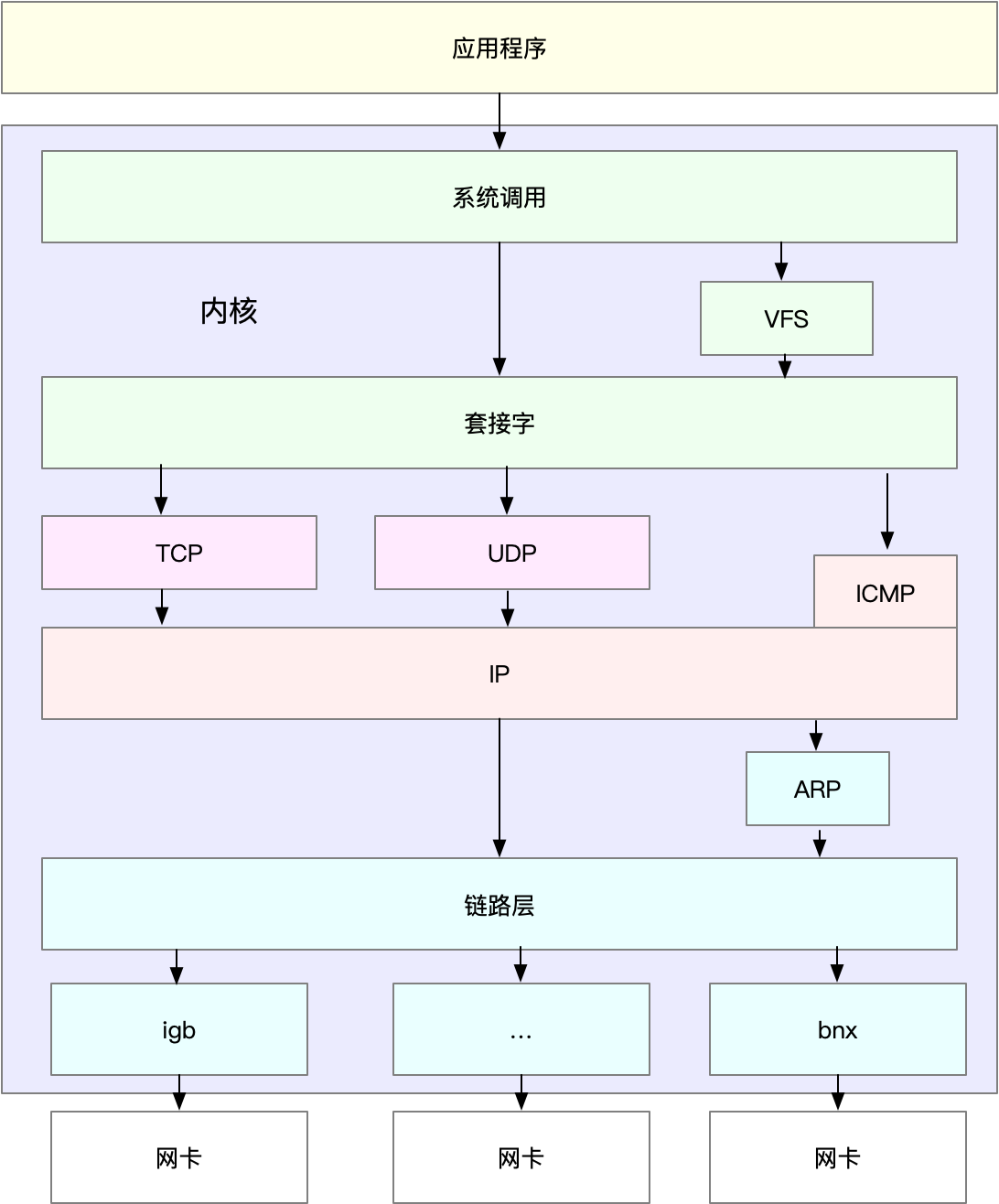
3.1 应用层
应用层即我们使用的网络库,常见问题主要有如下
- 网络I/O模型:使用
epoll或者IOCP的方式是否有问题,超过C10K的单机并发数,可考虑改为dpdk或者xdp - 进程工作模型:采用的是主进程+多个worker子进程还是多进程监听相同端口。如果是第一种是否存在进程间通信的延时问题,是否存在不必要的广播,是否出现通信失败导致进程工作阻塞?如果是第二种是否存在请求负载均衡的处理问题?
- 使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度。
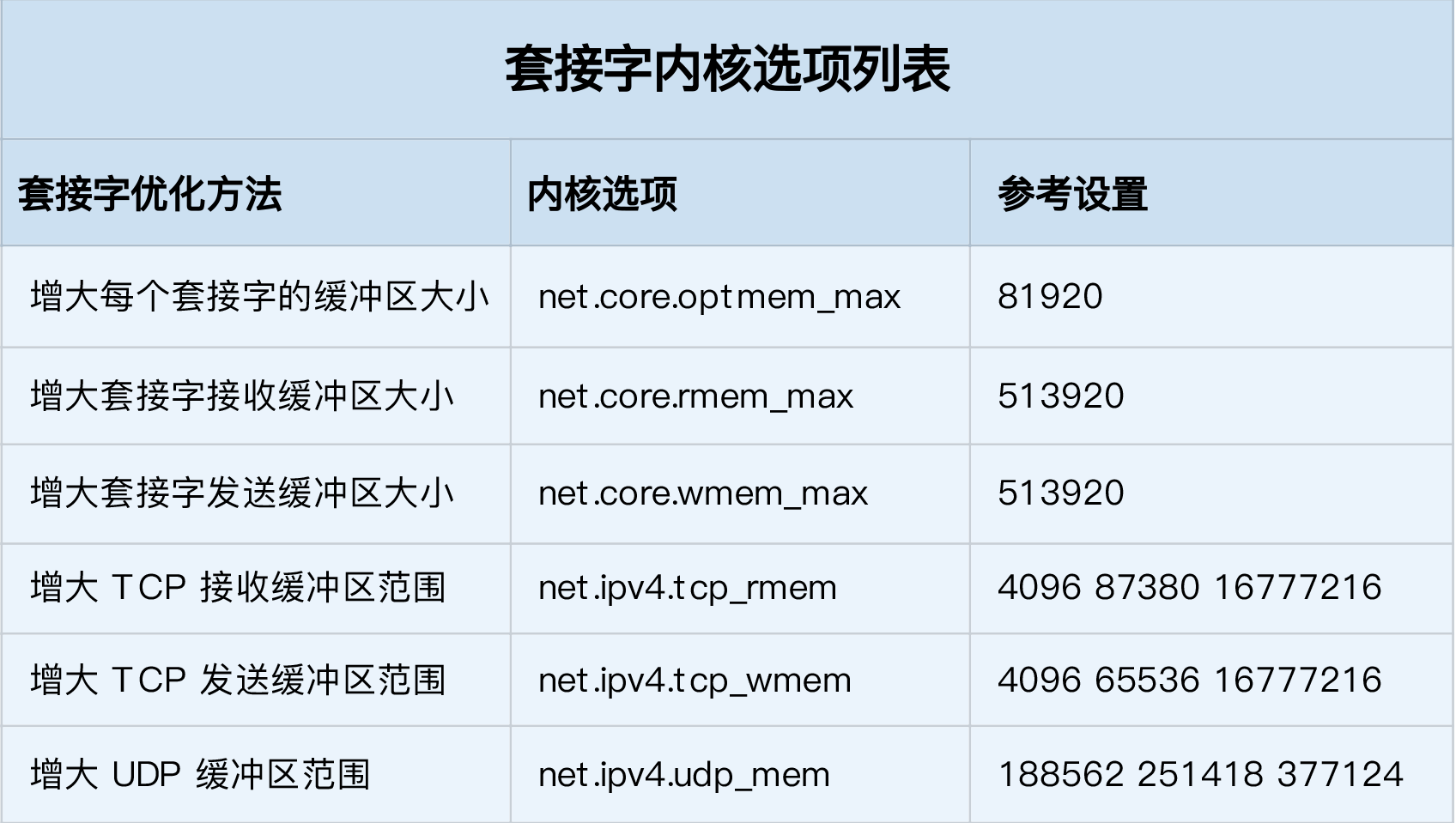
3.2 套接字层
为了提高网络的吞吐量,通常需要调整这些缓冲区的大小。比如:
- 增大每个套接字的缓冲区大小
net.core.optmem_max; - 增大套接字接收缓冲区大小
net.core.rmem_max和发送缓冲区大小net.core.wmem_max; - 增大 TCP 接收缓冲区大小
net.ipv4.tcp_rmem和发送缓冲区大小net.ipv4.tcp_wmem。 - 调整接收方的接收窗口最大值
net.ipv4.tcp_windows_scaling
注意:
tcp_rmem和tcp_wmem的三个数值分别是min,default,max,系统会根据这些设置,自动调整 TCP 接收 / 发送缓冲区的大小。udp_mem的三个数值分别是min,pressure,max,系统会根据这些设置,自动调整 UDP 发送缓冲区的大小。- 为
TCP连接设置TCP_NODELAY后,就可以禁用Nagle算法。 - 为
TCP连接开启TCP_CORK后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送)。 - 使用
SO_SNDBUF和SO_RCVBUF,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
3.3 传输层
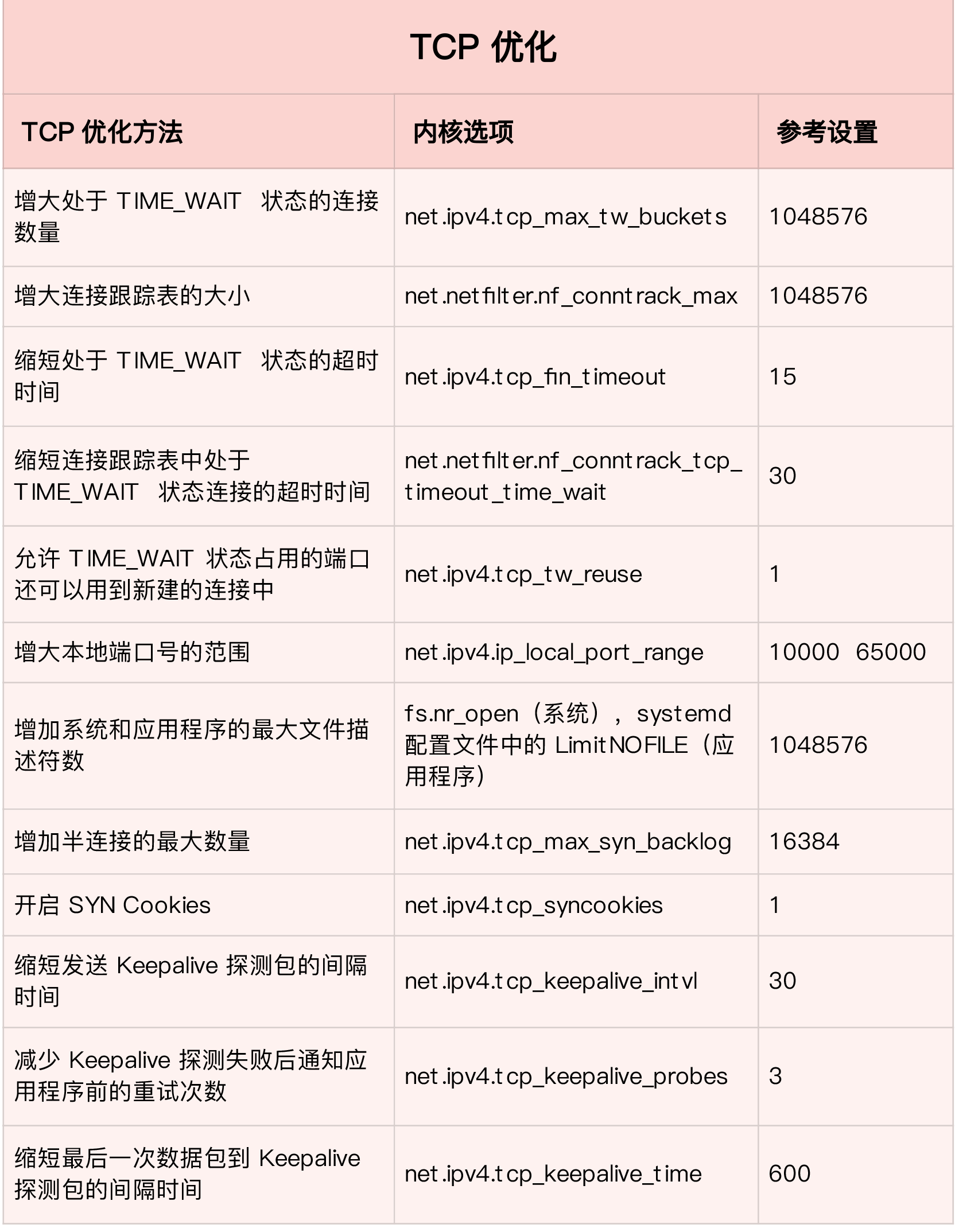
传输层优化分TCP和UDP。其中UDP又有可靠UDP的选择,如QUIC等。下面主要分析TCP优化,关于可靠UDP需要单独开文章分析。关于TCP的优化这里先列举大致的方法,在后面会详细讲解其中的部分。
TIME_WAIT优化。在请求数比较大的场景下,可能会看到大量处于TIME_WAIT状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与TIME_WAIT状态相关的内核选项,比如采取下面几种措施。
- 增大处于
TIME_WAIT状态的连接数量net.ipv4.tcp_max_tw_buckets,并增大连接跟踪表的大小net.netfilter.nf_conntrack_max。 - 减小
net.ipv4.tcp_fin_timeout和net.netfilter.nf_conntrack_tcp_timeout_time_wait,让系统尽快释放它们所占用的资源。 - 开启端口复用
net.ipv4.tcp_tw_reuse。这样,被TIME_WAIT状态占用的端口,还能用到新建的连接中。 - 增大本地端口的范围
net.ipv4.ip_local_port_range。这样就可以支持更多连接,提高整体的并发能力。 - 增加最大文件描述符的数量。你可以使用
fs.nr_open和fs.file-max,分别增大进程和系统的最大文件描述符数;或在应用程序的systemd配置文件中,配置LimitNOFILE,设置应用程序的最大文件描述符数。
- 为了缓解
SYN FLOOD等,利用 TCP 协议特点进行攻击而引发的性能问题,可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
- 增大 TCP 半连接的最大数量
net.ipv4.tcp_max_syn_backlog,或者开启TCP SYN Cookies net.ipv4.tcp_syncookies,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。 - 减少 SYN_RECV 状态的连接重传
SYN+ACK包的次数net.ipv4.tcp_synack_retries。
- 在长连接的场景中,通常使用
Keepalive来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候需要优化与Keepalive相关的内核选项,比如:
- 缩短最后一次数据包到
Keepalive探测包的间隔时间net.ipv4.tcp_keepalive_time; - 缩短发送
Keepalive探测包的间隔时间net.ipv4.tcp_keepalive_intvl;减少Keepalive探测失败后,一直到通知应用程序前的重试次数net.ipv4.tcp_keepalive_probes。
3.4 网络层
- 从路由和转发的角度出发,可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置
net.ipv4.ip_forward= 1。 - 调整数据包的生存周期 TTL,比如设置
net.ipv4.ip_default_ttl= 64。注意,增大该值会降低系统性能。 - 开启数据包的反向地址校验,比如设置
net.ipv4.conf.eth0.rp_filter= 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的大小。通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为 1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。在使用 VXLAN、GRE 等叠加网络技术时,要注意,网络叠加会使原来的网络包变大,导致 MTU 也需要调整。比如,就以 VXLAN 为例,它在原来报文的基础上,增加了 14B 的以太网头部、 8B 的 VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包比原来增大了 50B。所以,我们就需要把交换机、路由器等的 MTU,增大到 1550, 或者把 VXLAN 封包前(比如虚拟化环境中的虚拟网卡)的 MTU 减小为 1450。另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把 MTU 调大为 9000,以提高网络吞吐量。
从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问题,你可以通过内核选项,来限制 ICMP 的行为。比如,
- 禁止 ICMP 协议,即设置
net.ipv4.icmp_echo_ignore_all= 1。这样,外部主机就无法通过 ICMP 来探测主机。 - 禁止广播 ICMP,即设置
net.ipv4.icmp_echo_ignore_broadcasts= 1。
3.5 链路层
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。这通常可以采用下面两种方法。比如,
- 为网卡硬中断配置 CPU 亲和性(
smp_affinity),或者开启irqbalance服务。 - 开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
- VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。
对于网络接口本身,也有很多方法,可以优化网络的吞吐量。比如,
- 开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 使用 Traffic Control 工具,为不同网络流量配置
QoS。
3.7 协议之外
最后,在单机并发 1000 万的场景中,对 Linux 网络协议栈进行的各种优化策略,基本都没有太大效果。因为这种情况下,网络协议栈的冗长流程,其实才是最主要的性能负担。这时,我们可以用两种方式来优化。
- 第一种,使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
- 第二种,使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
四. 关于DDOS
从攻击的原理上来看,DDoS 可以分为下面几种类型。
- 第一种,耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。对于流量型的 DDoS 来说,当服务器的带宽被耗尽后,在服务器内部处理就无能为力了。这时,只能在服务器外部的网络设备中,设法识别并阻断流量(当然前提是网络设备要能扛住流量攻击)。比如,购置专业的入侵检测和防御设备,配置流量清洗设备阻断恶意流量等。
- 第二种,耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正常的网络连接。对于该种攻击,比较好的处理方式是基于 XDP 或者 DPDK,构建 DDoS 方案,在内核网络协议栈前,或者跳过内核协议栈,来识别并丢弃 DDoS 报文,避免 DDoS 对系统其他资源的消耗。也可以采取SYN COOKIE等方式紧急处理。
- 第三种,消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响应。这种需要应用程序考虑识别,并尽早拒绝掉这些恶意流量,比如合理利用缓存、增加 WAF(Web Application Firewall)、使用 CDN 等等。
五. 丢包和掉线排查
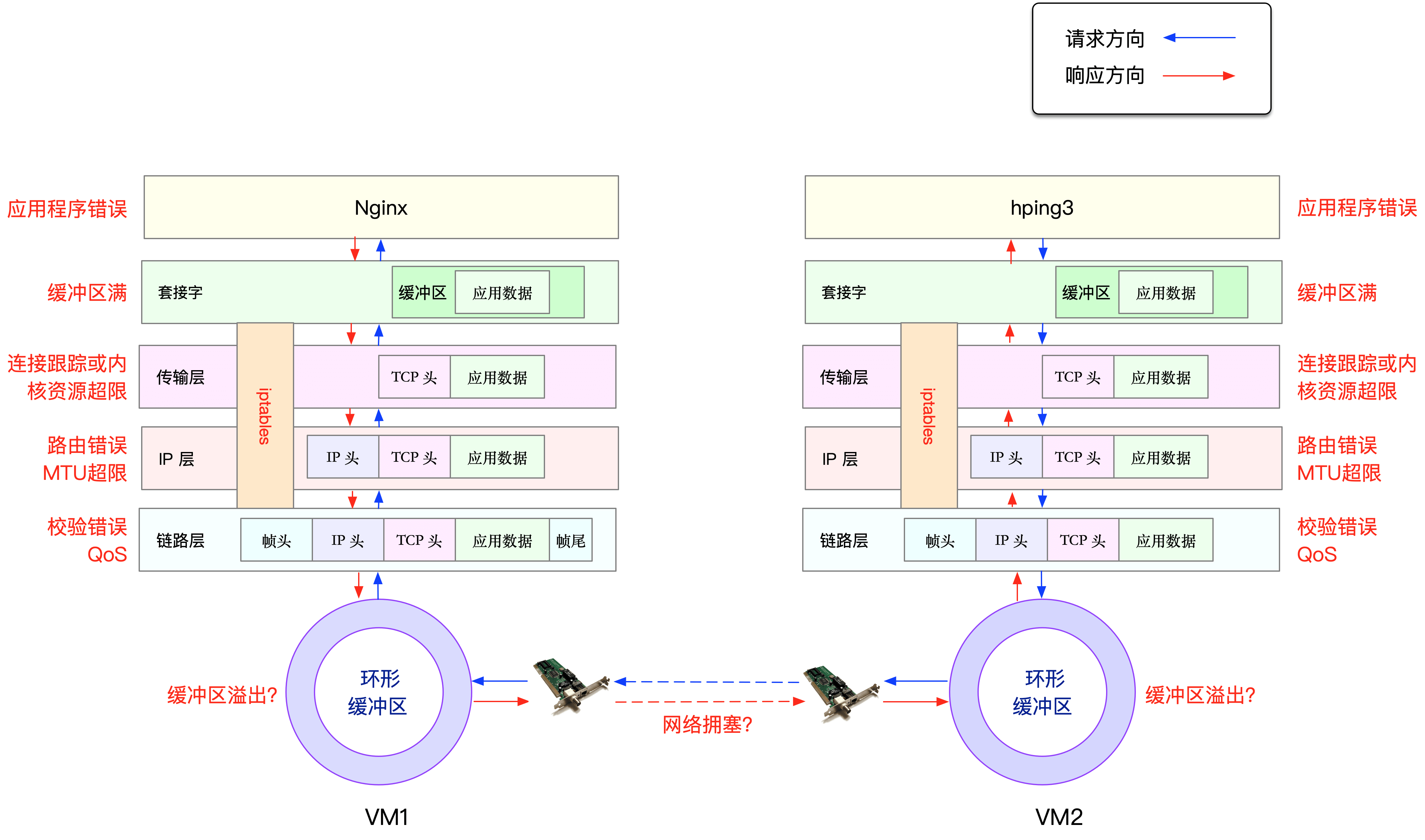
从图中可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。比如我们从下往上看:
- 在两台PC连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;(
netstat -i) - 在链路层,可能会因为网络帧校验失败、
QoS等而丢包; - 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;(
sysctl net.ipv4.ip_local_port_range) - 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;(
netstat -s,ss -s,ss -ltnp) - 在套接字层,可能会因为套接字缓冲区溢出而丢包;(
dmesg | tail) - 在应用层,可能会因为应用程序异常而丢包;(
tc -s qdisc show dev eth0,perf record -g) - 此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。(
sysctl net.netfilter.nf_conntrack_max,sysctl net.netfilter.nf_conntrack_count,iptables -t filter -nvL)
所以在实际工作中对于丢包、掉线问题的排查需要先排除不可能出现问题的地方,然后根据众多性能参数和Log日志逐一进行排查,对存有疑虑的地方进行重点追踪。
六. 传输层优化详解
6.1 三次握手
- SYN_RECV状态
三次握手的源码机制在前文中已经详细叙述,其中SYN_RECV下要点主要在于半连接队列可能会被大量新建连接挤爆掉,这个可通过netstat -s | grep "SYNs to LISTEN"进行查询。对应的修改方法是修改队列大小,即net.ipv4.tcp_max_syn_backlog或者采用SYN COOKIES。修改 tcp_syncookies 参数即可启动syn cookie功能,其中值为 0 时表示关闭该功能,2 表示无条件开启功能,而 1 则表示仅当 SYN 半连接队列放不下时,再启用它。由于 syncookie 仅用于应对 SYN 泛洪攻击(攻击者恶意构造大量的 SYN 报文发送给服务器,造成 SYN 半连接队列溢出,导致正常客户端的连接无法建立),这种方式建立的连接,许多 TCP 特性都无法使用。所以,应当把 tcp_syncookies 设置为 1,仅在队列满时再启用。
- ESTABLISH
三次握手结束,半连接队列中的连接会被移至全连接队列等待accept()函数获取。如果进程不能及时地调用 accept ()函数,就会造成 accept 队列溢出,最终导致建立好的 TCP 连接被丢弃。netstat -s | grep "listen queue"可以看到究竟有多少个连接因为队列溢出而被丢弃。实际上,丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。打开这一功能需要将 net.ipv4.tcp_abort_on_overflow 参数设置为 1。
但是通常情况下,应当把 tcp_abort_on_overflow 设置为 0,因为这样更有利于应对突发流量。举个例子,当 accept 队列满导致服务器丢掉了 ACK,与此同时,客户端的连接状态却是 ESTABLISHED,进程就在建立好的连接上发送请求。只要服务器没有为请求回复 ACK,请求就会被多次重发。如果服务器上的进程只是短暂的繁忙造成 accept 队列满,那么当 accept 队列有空位时,再次接收到的请求报文由于含有 ACK,仍然会触发服务器端成功建立连接。所以,tcp_abort_on_overflow 设为 0 可以提高连接建立的成功率,只有非常肯定 accept 队列会长期溢出时,才能设置为 1 以尽快通知客户端。
修改accept 队列的长度需要修改listen() 函数的 backlog 参数。事实上,backlog 参数还受限于 Linux 系统级的队列长度上限,当然这个上限阈值也可以通过 net.core.somaxconn 参数修改。
- 绕过三次握手
TFO由谷歌提出,为解决多次连接时三次握手导致的流量损耗问题。把通讯分为两个阶段,第一阶段为首次建立连接,这时走正常的三次握手,但在客户端的 SYN 报文会明确地告诉服务器它想使用 TFO 功能,这样服务器会把客户端 IP 地址用只有自己知道的密钥加密(比如 AES 加密算法),作为 Cookie 携带在返回的 SYN+ACK 报文中,客户端收到后会将 Cookie 缓存在本地。之后,如果客户端再次向服务器建立连接,就可以在第一个 SYN 报文中携带请求数据,同时还要附带缓存的 Cookie。很显然,这种通讯方式下不能再采用经典的“先 connect() 再 write() 请求”这种编程方法,而要改用 sendto() 或者 sendmsg() 函数才能实现。
Linux 下打开 TFO 功能要通过 net.ipv4.tcp_fastopen 参数。由于只有客户端和服务器同时支持时,TFO 功能才能使用,所以 tcp_fastopen 参数是按比特位控制的。其中,第 1 个比特位为 1 时,表示作为客户端时支持 TFO;第 2 个比特位为 1 时,表示作为服务器时支持 TFO,所以当 tcp_fastopen 的值为 3 时(比特为 0x11)就表示完全支持 TFO 功能。
6.2 四次挥手
close() 和 shutdown() 函数都可以关闭连接,但这两种方式关闭的连接,不只功能上有差异,控制它们的 Linux 参数也不相同。close() 函数会让连接变为孤儿连接,shutdown() 函数则允许在半关闭的连接上长时间传输数据。TCP 之所以具备这个功能,是因为它是全双工协议,但这也造成四次挥手非常复杂。
- FIN_WAIT1数量异常
当主动断开方发出FIN后就会进入FIN_WAIT1状态,直至收到ACK才会进入FIN_WAIT2,该过程通常会在数十毫秒内完成,因此如果发现大量处于该状态的连接,则肯定是不正常的。如果 FIN_WAIT1 状态连接有很多,就需要考虑降低 net.ipv4.tcp_orphan_retries 的值。当重试次数达到 tcp_orphan_retries 时,连接就会直接关闭掉。
对于正常情况来说,调低 tcp_orphan_retries 已经够用,但如果遇到恶意攻击,FIN 报文根本无法发送出去。这是由 TCP 的 2 个特性导致的。
- 首先,TCP 必须保证报文是有序发送的,FIN 报文也不例外,当发送缓冲区还有数据没发送时,FIN 报文也不能提前发送。
- 其次,TCP 有流控功能,当接收方将接收窗口设为 0 时,发送方就不能再发送数据。所以,当攻击者下载大文件时,就可以通过将接收窗口设为 0,导致 FIN 报文无法发送,进而导致连接一直处于 FIN_WAIT1 状态。
解决这种问题的方案是调整 net.ipv4.tcp_max_orphans参数:tcp_max_orphans 定义了孤儿连接的最大数量。当进程调用 close 函数关闭连接后,无论该连接是在 FIN_WAIT1 状态,还是确实关闭了,这个连接都与该进程无关了,它变成了孤儿连接。Linux 系统为防止孤儿连接过多,导致系统资源长期被占用,就提供了 tcp_max_orphans 参数。如果孤儿连接数量大于它,新增的孤儿连接将不再走四次挥手,而是直接发送 RST 复位报文强制关闭。
- TIME_WAIT数量过多
关于TIME_WAIT的意义在前文中已经详细叙述。Linux 提供了 tcp_max_tw_buckets 参数,当 TIME_WAIT 的连接数量超过该参数时,新关闭的连接就不再经历 TIME_WAIT 而直接关闭。当服务器的并发连接增多时,相应地,同时处于 TIME_WAIT 状态的连接数量也会变多,此时就应当调大 tcp_max_tw_buckets 参数,减少不同连接间数据错乱的概率。
当然,tcp_max_tw_buckets 也不是越大越好,毕竟内存和端口号都是有限的。有没有办法让新连接复用 TIME_WAIT 状态的端口呢?如果服务器会主动向上游服务器发起连接的话,就可以把 tcp_tw_reuse 参数设置为 1,它允许作为客户端的新连接,在安全条件下使用 TIME_WAIT 状态下的端口。当然,要想使 tcp_tw_reuse 生效,还得把 timestamps 参数设置为 1,它满足安全复用的先决条件(对方也要打开 tcp_timestamps )。
- CLOSE_WAIT数量过多
当被动方收到 FIN 报文时,就开启了被动方的四次挥手流程。内核自动回复 ACK 报文后,连接就进入 CLOSE_WAIT 状态,顾名思义,它表示等待进程调用 close 函数关闭连接。内核没有权力替代进程去关闭连接,因为若主动方是通过 shutdown 关闭连接,那么它就是想在半关闭连接上接收数据。因此,Linux 并没有限制 CLOSE_WAIT 状态的持续时间。
当然,大多数应用程序并不使用 shutdown 函数关闭连接,所以,当你用 netstat 命令发现大量 CLOSE_WAIT 状态时,要么是程序出现了 Bug,read 函数返回 0 时忘记调用 close 函数关闭连接,要么就是程序负载太高,close 函数所在的回调函数被延迟执行了。此时,我们应当在应用代码层面解决问题。由于 CLOSE_WAIT 状态下,连接已经处于半关闭状态,所以此时进程若要关闭连接,只能调用 close 函数(再调用 shutdown 关闭单向通道就没有意义了),内核就会发出 FIN 报文关闭发送通道,同时连接进入 LAST_ACK 状态,等待主动方返回 ACK 来确认连接关闭。
6.3 通信过程
TCP通信是一个复杂的过程。我们知道,TCP 必须保证每一个报文都能够到达对方,它采用的机制就是:报文发出后,必须收到接收方返回的 ACK 确认报文(Acknowledge 确认的意思)。如果在一段时间内(称为 RTO,retransmission timeout)没有收到,这个报文还得重新发送,直到收到 ACK 为止。可见,TCP 报文发出去后,并不能立刻从内存中删除,因为重发时还需要用到它。由于 TCP 是由内核实现的,所以报文存放在内核缓冲区中,这也是高并发下 buff/cache 内存增加很多的原因。在此过程中,我们需要关注的是缓冲区的大小。其源码在原文中已经详细分析,下面简单摘取其中TCP相关的逻辑。
tcp_sendmsgsk_stream_wait_memory若内核缓存不足则按超时时间指示等待tcp_sendmsg拷贝用户态数据到内核态发送缓存中
tcp_pushtcp_cwnd_test检查飞行中的报文个数是否超过拥塞窗口tcp_snd_wnd_test检查待发的序号是否超过发送窗口tcp_nagle_test检查nagle算法是否可以发送tcp_window_allows检查待发送的报文长度是否超过拥塞窗口和发送窗口的最小值tcp_transmit_skb调用IP层的方法发送报文
如果sendbuffer不够就会卡在上图中的第一步 sk_stream_wait_memory, 通过systemtap脚本可以验证:
1 | !/usr/bin/stap |
6.4 拥塞控制
- 加快慢启动
拥塞控制的状态可以通过ss查看
1 | ss -nli|fgrep cwnd |
再通过 ip route change 命令修改初始拥塞窗口:
1 | ip route | while read r; do |
- 修改拥塞控制算法
1 | net.ipv4.tcp_congestion_control = cubic |
总结
网络优化是一个极为复杂的事,需要了解业务代码,了解Linux网络协议栈的内容和源码,并掌握很多测试工具,在此基础上小心翼翼地排查瓶颈和问题所在并尝试优化。但是这也是一件极为有趣的事,希望大家都能取得极好的性能优化效果。
参考文献
[1] Linux-insides
[2] 深入理解Linux内核
[3] Linux内核设计的艺术
[4] 深入理解计算机系统
[5] 深入理解Linux网络技术内幕
[6] shell脚本编程大全
[7] 极客时间 Linux性能优化实战
[8] 极客时间 系统性能调优必知必会

