一. 前言
前文分析到Linux内核正式启动,完成了实模式到保护模式的切换,并做好了各种准备工作。下来就要看开始内核初始化工作了,源码位置位于init/main.c中的start_kernel(),源码如附录所示。这包括了一系列重要的初始化工作,本文会介绍其中一部分较为重要的,但是详细的介绍依然会留在后文各个模块的源码学习中单独进行。本文的目的在于承接上文给出一个从内核启动到各个模块开始运转的过程介绍,而不是详细的各部分内容介绍。
创建0号进程:
INIT_TASK(init_task)异常处理类中断服务程序挂接:
trap_init()内存初始化:
mm_init()调度器初始化
sched_init()剩余初始化:
rest_init()
二. 0号进程的创建
start_kernel()上来就会运行 set_task_stack_end_magic(&init_task)创建初始进程。init_task的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为 0 号进程。这是唯一一个没有通过 fork 或者 kernel_thread产生的进程,是进程列表的第一个。
如下所示为init_task的定义,这里只节选了部分,采用了gcc的结构体初始化方式为其进行了直接赋值生成。
1 | /* |
而 set_task_stack_end_magic(&init_task)函数的源码如下,主要是通过end_of_stack()获取栈边界地址,然后把栈底地址设置为STACK_END_MAGIC,作为栈溢出的标记。每个进程创建的时候,系统会为这个进程创建2个页大小的内核栈。
1 | void set_task_stack_end_magic(struct task_struct *tsk) |
init_task是静态定义的一个进程,也就是说当内核被放入内存时,它就已经存在,它没有自己的用户空间,一直处于内核空间中运行,并且也只处于内核空间运行。0号进程用于包括内存、页表、必要数据结构、信号、调度器、硬件设备等的初始化。当它执行到最后(剩余初始化)时,将start_kernel中所有的初始化执行完成后,会在内核中启动一个kernel_init内核线程和一个kthreadd内核线程,kernel_init内核线程执行到最后会通过execve系统调用执行转变为我们所熟悉的init进程,而kthreadd内核线程是内核用于管理调度其他的内核线程的守护线程。在最后init_task将变成一个idle进程,用于在CPU没有进程运行时运行它,它在此时仅仅用于空转。
三. 中断初始化
由代码可见,trap_init()设置了很多的中断门(Interrupt Gate),用于处理各种中断,如系统调用的中断门set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32)。
1 | void trap_init(void) |
四. 内存初始化
内存相关的初始化内容放在mm_init()中进行,代码如下所示
1 | // init/main.c |
调用的函数功能基本如名字所示,主要进行了以下初始化设置:
page_ext_init_flatmem()和cgroup的初始化相关,该部分是docker技术的核心部分mem_init()初始化内存管理的伙伴系统kmem_cache_init()完成内核slub内存分配体系的初始化,相关的还有buffer_initpgtable_init()完成页表初始化,包括页表锁ptlock_init()和vmalloc_init()完成vmalloc的初始化ioremap_huge_init()ioremap实现I/O内存资源由物理地址映射到虚拟地址空间,此处为其功能的初始化init_espfix_bsp()和pti_init()完成PTI(page table isolation)的初始化
此处不展开说明这些函数,留待后面内存管理部分详细分析各个部分。
五. 调度器初始化
调度器初始化通过sched_init()完成,其主要工作包括
对相关数据结构分配内存:如初始化
waitqueues数组,根据调度方式FAIR/RT设置alloc_size,调用kzalloc分配空间初始化
root_task_group:根据FAIR/RT的不同,将kzalloc分配的空间用于其初始化,主要结构task_group包含以下几个重要组成部分:se,rt_se,cfs_rq以及rt_rq。其中cfs_rq和rt_rq表示run queue,即一种特殊的per-cpu结构体用于内核调度器存储激活的线程。调用
for_each_possible_cpu()初始化每个possibleCPU(存储于cpu_possible_mask为图中)的runqueue队列(包括其中的cfs队列和实时进程队列),rq结构体是调度进程的基本数据结构,调度器用rq决定下一个将要被调度的进程。详细介绍会在调度一节进行。调用
set_load_weight(&init_task),将init_task进程转变为idle进程需要说明的是
init_task在这里会被转变为idle进程,但是它还会继续执行初始化工作,相当于这里只是给init_task挂个idle进程的名号,它其实还是init_task进程,只有到最后init_task进程开启了kernel_init和kthreadd进程之后,才转变为真正意义上的idle进程。
六. 剩余初始化
rest_init是非常重要的一步,主要包括了区分内核态和用户态、初始化1号进程和初始化2号进程。
6.1 内核态和用户态
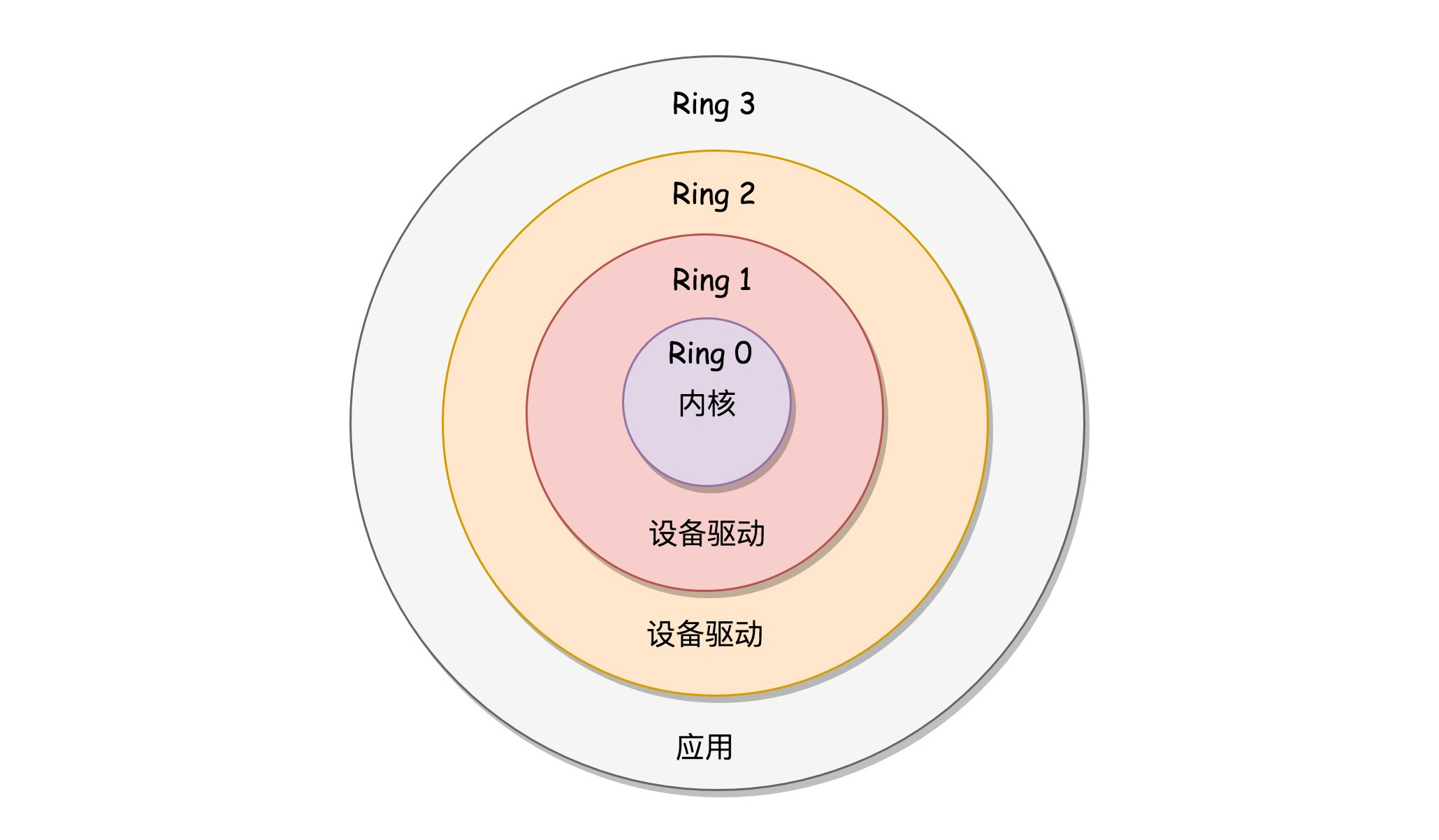
在运行用户进程之前,尚需要完成一件事:区分内核态和用户态。x86 提供了分层的权限机制,把区域分成了四个 Ring,越往里权限越高,越往外权限越低。操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。
6.2 初始化1号进程
rest_init() 的一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS)创建第二个进程,这个是 1 号进程。1 号进程对于操作系统来讲,有“划时代”的意义,因为它将运行一个用户进程,并从此开始形成用户态进程树。这里主要需要分析的是如何完成从内核态到用户态切换的过程。kernel_thread()代码如下所示,可见其中最主要的是第一个参数指针函数fn决定了栈中的内容,根据fn的不同将生成1号进程和后面的2号进程。
1 | /* |
kernel_thread() 的参数是一个函数 kernel_init(),核心代码如下:
1 | if (ramdisk_execute_command) |
这就说明,1 号进程运行的是一个文件。如果我们打开 run_init_process() 函数,会发现它调用的是 do_execve()。
1 | static int run_init_process(const char *init_filename) |
接着会进行一系列的调用:do_execve->do_execveat_common->exec_binprm->search_binary_handler,这里search_binary_handler()主要是加载ELF文件(Executable and Linkable Format,可执行与可链接格式),代码如下
1 | int search_binary_handler(struct linux_binprm *bprm) |
load_binary先调用load_elf_binary,最后调用start_thread
1 |
|
这个结构就是在系统调用的时候,内核中保存用户态运行上下文的,里面将用户态的代码段 CS 设置为 __USER_CS,将用户态的数据段 DS 设置为 __USER_DS,以及指令指针寄存器 IP、栈指针寄存器 SP。这里相当于补上了原来系统调用里,保存寄存器的一个步骤。最后的 iret 是干什么的呢?它是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS 和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句。DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。
经过上述过程,我们完成了从内核态切换到用户态。而此时代码其实还在运行 kernel_init函数,会调用
1 | if (!ramdisk_execute_command) |
结合上面的init程序,这里出现了第二个init。这是有其存在的必要性的:上文提到的 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是 ramdisk。这个时候,ramdisk 是根文件系统。然后,我们开始运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
6.3 初始化2号进程
rest_init 另一大事情就是创建第三个进程,就是 2 号进程。kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)又一次使用 kernel_thread 函数创建进程。这里需要指出一点,函数名 thread 可以翻译成“线程”,这也是操作系统很重要的一个概念。从内核态来看,无论是进程,还是线程,我们都可以统称为任务(Task),都使用相同的数据结构,平放在同一个链表中。这里的函数kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
kthreadd,即2号进程,用于内核态线程的管理,是一个守护线程。其源码如下所示,运行流程包括
- 初始化了
task结构,并将该线程设置为允许任意CPU运行。 - 进入循环,将线程状态设置为
TASK_INTERRUPTIBLE,如果当前kthread_create_list为空,没有要创建的线程,则执行schedule()让出CPU资源。 - 如果需要创建,则设置为
TASK_RUNNING状态,加上锁spin_lock,从链表中取得kthread_create_info结构的地址,在上文中已经完成插入操作(将kthread_create_info结构中的 list 成员加到链表中,此时根据成员 list 的偏移获得 create) - 调用
create_kthread(create)完成线程的创建
1 | int kthreadd(void *unused) |
而create_kthread(create)函数做了一件让人意外的事情:调用了kernel_thread(),所以又回到了创建1号进程和2号进程的函数上,这次的回调函数为kthread,该函数才会真正意义上分配内存、初始化一个新的内核线程。
1 | static void create_kthread(struct kthread_create_info *create) |
下面是kthread的源码,这里有个很重要的地方:新创建的线程由于执行了 schedule() 调度,此时并没有执行,直到我们使用wake_up_process(p)唤醒新创建的线程。线程被唤醒后, 会接着执行最后一段threadfn(data)
1 | static int kthread(void *_create) |
由此,我们可以总结一下第2号进程的工作流程:
- 第2号进程
kthreadd进程由第0号进程通过kernel_thread()创建,并始终运行在内核空间, 负责所有内核线程的调度和管理 - 第2号进程会循环检测
kthread_create_list全局链表, 当我们调用kernel_thread创建内核线程时,新线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程 - 检测到新线程创建,则调用
kernel_thread()创建线程,其回调为kthread kthread在创建完后调用schedule()让出CPU资源,而不是直接运行。等待收到wake_up_process(p)的唤醒后再继续执行threadfn(data)。
因此
任何一个内核线程入口都是 kthread()
通过
kthread_create()创建的内核线程不会立刻运行,需要手工wake up.通过
kthread_create()创建的内核线程有可能不会执行相应线程函数threadfn而直接退出
回到rest_init(),当完成了1号2号进程的创建后,我们将0号进程真正归位idle进程,结束rest_init(),也正事结束了start_kernel()函数,由此,内核初始化全部完成。
七. 总结
本文介绍了内核初始化的几个重要部分,其实还有很多初始化没有介绍,如cgroup初始化、虚拟文件系统初始化、radix树初始化、rcu初始化、计时器和时间初始化、架构初始化等等,这些会在后面有针对性的单独介绍。
源码资料
[1] init/main.c
参考资料
[1] Linux-insides
[2] 深入理解Linux内核
[3] Linux内核设计的艺术
[4] 极客时间 趣谈Linux操作系统

