一. 前言
众所周知,System V IPC进程间通信机制体系中有着多种多样的进程间通信方式,如管道和有名管道,消息队列,信号,共享内存和信号量,套接字。从本文开始我们就逐个剖析进程间通信的机制和底层原理,就从信号开始讲起吧。
二. 信号基本知识
信号是进程处理紧急情况所用的一种方式,它没有特别复杂的数据结构,就是用一个代号一样的数字。Linux 提供了几十种信号,分别代表不同的意义。我们可以通过kill -l命令查看信号。
1 |
|
信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就默认执行这个函数就可以了。通过man 7 signal可以查看各个信号的具体含义和对应的处理方法
1 | Signal Value Action Comment |
由上表可见,信号的处理通常分为三种:
执行默认操作。Linux 对每种信号都规定了默认操作,例如上面列表中的
Term,就是终止进程的意思。Core的意思是Core Dump,也即终止进程后通过Core Dump将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。捕捉信号。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
忽略信号。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即
SIGKILL和SEGSTOP,它们用于在任何时候中断或结束某一进程。
三. 信号和中断
信号和中断有着诸多相似之处:
- 均会注册处理函数
- 都是用于对当前的任务进行一些处理,如调度、停止等等
但是二者实际上是有很多不同的,其不同的用途导致了运行逻辑的不同,最终在代码实现上体现出了不同的设计特点。其主要区别有:
- 中断和信号都可能源于硬件和软件,但是中断处理函数注册于内核之中,由内核中运行,而信号的处理函数注册于用户态,内核收到信号后会根据当前任务
task_struct结构体中的信号相关数据结构找寻对应的处理函数并最终在用户态处理 - 中断作用于内核全局,而信号作用于当前任务(进程)。即信号影响的往往是一个进程,而中断处理如果出现问题则会导致整个Linux内核的崩溃
四. 注册信号处理函数
有些时候我们希望能够让信号运行一些特殊功能,所以有了自定义的信号处理函数。注册API主要有signal()和sigaction()两个,其中sigaction()比较推荐使用。
1 | typedef void (*sighandler_t)(int); |
其主要区别在于sigaction()对于信号signum会绑定对应的结构体sigaction而不仅仅是一个处理函数sighandler_t。这样做的好处是可以更精细的控制信号处理,通过不同参数实现不同的效果。例如sa_flags可以设置如
SA_ONESHOT:信号处理函数仅作用一次,之后启用默认行为SA_NOMASK:该信号处理函数执行过程中允许被其他信号或者相同信号中断,即不屏蔽SA_INTERRUPT:该信号处理函数若执行过程中被中断,则不会再调度回该函数继续执行,而是直接返回-EINTR,将执行逻辑交还给调用方SA_RESTART:与SA_INTERRUPT相反,会自动重启该函数
sa_restorer保存的是sa_handler 执行完毕之后,马上要执行的函数,即下一个函数地址的位置。
1 | struct sigaction { |
sigaction()也是glibc封装的函数,最终系统调用为rt_sigaction()。该函数首先将用户态的 struct sigaction 结构拷贝为内核态的 k_sigaction,然后调用 do_sigaction()设置对应的信号处理动作。
1 | SYSCALL_DEFINE4(rt_sigaction, int, sig, |
do_sigaction()会将用户层传来的信号处理函数赋值给当前任务task_struct currrent对应的sighand->action[]数组中sig信号对应的位置,以用于之后调用。
1 | int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact) |
五. 发送信号
信号发送来源广泛,有可能来自于用户态,有可能来自于硬件,也有可能来自于内核。
- 有时候,我们在终端输入某些组合键的时候会给进程发送信号,例如,Ctrl+C 产生 SIGINT 信号,Ctrl+Z 产生 SIGTSTP 信号。再比如,
kill -9 pid可以发送信号给一个进程,杀死它。 - 有的时候,硬件异常也会产生信号。比如,执行了除以 0 的指令,CPU 就会产生异常,然后把 SIGFPE 信号发送给进程。再如,进程访问了非法内存,内存管理模块就会产生异常,然后把信号 SIGSEGV 发送给进程。
- 有时候,内核在某些情况下,也会给进程发送信号。例如,向读端已关闭的管道写数据时产生 SIGPIPE 信号,当子进程退出时,我们要给父进程发送 SIG_CHLD 信号等。
不论通过kill或者sigqueue系统调用还是通过tkill或者tgkill发送指定线程的信号,其最终调用的均是do_send_sig_info()函数,其调用链如下所示
1 | kill()->kill_something_info()->kill_pid_info()->group_send_sig_info()->do_send_sig_info() |
do_send_sig_info() 会调用 send_signal(),进而调用 __send_signal()。这里代码比较复杂,主要逻辑如下
- 根据发送信号的类型判断是共享信号还是线程独享信号,由此赋值
pending。如果是kill发送的,也就是发送给整个进程的,就应该发送给t->signal->shared_pending,这里面是整个进程所有线程共享的信号;如果是tkill发送的,也就是发给某个线程的,就应该发给t->pending,这里面是这个线程的 task_struct 独享的。 - 调用
legacy_queue()判断是否为可靠信号,不可靠则直接退出 - 调用
__sigqueue_alloc()分配一个struct sigqueue对象,然后通过list_add_tail挂在struct sigpending里面的链表上。 - 调用
complete_signal()分配线程处理该信号
1 | int do_send_sig_info(int sig, struct kernel_siginfo *info, struct task_struct *p, |
legacy_queue()中主要是判断是否为可靠信号,判断的依据是当信号小于 SIGRTMIN也即 32 的时候,如果我们发现这个信号已经在集合里面了,就直接退出。这里之所以前32位信号称之为不可靠信号其实是历史遗留问题,早期UNIX系统只定义了32种信号,而这些经过检验被定义为不可靠信号,主要指的是进程可能对信号做出错误的反应以及信号可能丢失:UNIX系统每次信号处理完需要重新安装信号,因此容易出现各种错误。linux也支持不可靠信号,但是对不可靠信号机制做出了改进:在调用完信号处理函数后,不必重新调用该信号的安装函数(信号安装函数是在可靠机制上是实现的)。因此,linux下的不可靠信号问题主要指的是信号可能丢失。
这里之所以会出现信号丢失,是因为这些信号可能会频繁快速出现。这样信号能够处理多少,和信号处理函数什么时候被调用,信号多大频率被发送,都有关系,而信号处理函数的调用时间也是不确定的,因此这种信号称之为不可靠信号。与之相对的,其他信号称之为可靠信号,支持排队执行。
1 | static inline int legacy_queue(struct sigpending *signals, int sig) |
对于可靠信号我们通过__sigqueue_alloc()分配sigqueue对象,并挂载在sigpending中的链表上,最终调用complete_signal()找一个线程处理。其主要逻辑为:
- 首先找是否有可唤醒的线程来执行,如果是主线程或者仅有一个线程,则直接从链表主队并分配
- 如果没找到可唤醒的线程,则查看当前是否有不需要唤醒的线程可以执行
- 如果没找到并且该信号为非常重要的信号如
SIGKILL,则强行关闭当前线程 - 调用
signal_wake_up()唤醒线程
1 | static void complete_signal(int sig, struct task_struct *p, enum pid_type type) |
signal_wake_up()函数主要逻辑为
- 设置
TIF_SIGPENDING标记位 - 尝试唤醒该线程/进程
信号处理的调度和任务调度类似,均是采用标记位的方式进行。当信号来的时候,内核并不直接处理这个信号,而是设置一个标识位 TIF_SIGPENDING来表示已经有信号等待处理。同样等待系统调用结束,或者中断处理结束,从内核态返回用户态的时候再进行信号的处理。
进程/线程的唤醒和任务调度一样最终会调用 try_to_wake_up() ,具体逻辑就不重复分析了。如果 wake_up_state 返回 0,说明进程或者线程已经是 TASK_RUNNING 状态了,如果它在另外一个 CPU 上运行,则调用 kick_process 发送一个处理器间中断,强制那个进程或者线程重新调度,重新调度完毕后,会返回用户态运行。
1 | static inline void signal_wake_up(struct task_struct *t, bool resume) |
六. 信号的处理
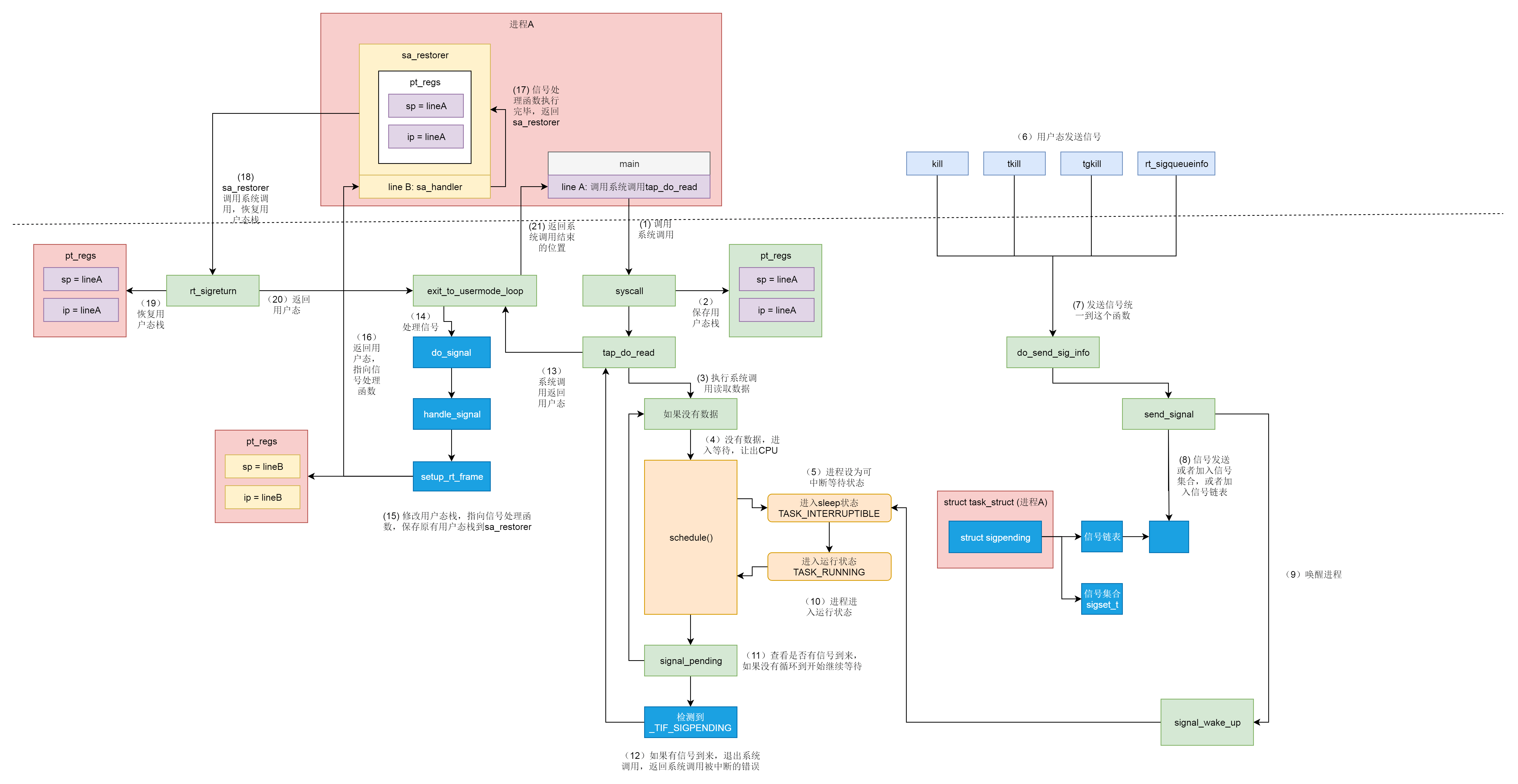
这里我们以一个从tap 网卡中读取数据的例子来分析信号的处理逻辑。这部分涉及到了系统调用、任务调度、中断等知识,对前面的文章也算是一个回顾。从网卡读取数据会通过系统调用进入内核,之后通过函数调用表找到对应的函数执行。在读的过程中,如果没有数据处理则会调用schedule()函数主动让出CPU进入休眠状态并等待再次唤醒。
tap_do_read()主要逻辑为:
- 把当前进程或者线程的状态设置为 TASK_INTERRUPTIBLE,这样才能使这个系统调用可以被中断。
- 可以被中断的系统调用往往是比较慢的调用,并且会因为数据不就绪而通过
schedule()让出 CPU 进入等待状态。在发送信号的时候,我们除了设置这个进程和线程的_TIF_SIGPENDING标识位之外,还试图唤醒这个进程或者线程,也就是将它从等待状态中设置为TASK_RUNNING。当这个进程或者线程再次运行的时候,会从schedule()函数中返回,然后再次进入while循环。由于这个进程或者线程是由信号唤醒的而不是因为数据来了而唤醒的,因而是读不到数据的,但是在signal_pending()函数中,我们检测到了_TIF_SIGPENDING标识位,这说明系统调用没有真的做完,于是返回一个错误ERESTARTSYS,然后带着这个错误从系统调用返回。 - 如果没有信号,则继续调用
schedule()让出CPU
1 | static ssize_t tap_do_read(struct tap_queue *q, |
schedule()会在系统调用返回或者中断返回的时刻调用exit_to_usermode_loop(),在任务调度中标记位为_TIF_NEED_RESCHED,而对于信号来说是_TIF_SIGPENDING。
1 | static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags) |
do_signal()函数会调用 handle_signal(),这里主要存在一个问题使得逻辑变得较为复杂:信号处理函数定义于用户态,而调度过程位于内核态。
1 | /* |
handle_signal()会判断当前是否从系统调用调度而来,当发现错误码为ERESTARTSYS的时候就知道这是从一个没有调用完的系统调用返回的,设置系统错误码为EINTR。由于此处不会直接返回任务调度前记录的用户态状态,而是进入注册好的信号处理函数,因此需要调用setup_rt_frame()构建新的寄存器结构体pt_regs。
1 | static void |
setup_rt_frame()主要调用__setup_rt_frame(),主要逻辑为:
- 调用
get_sigframe()得到regs中的sp寄存器值,即原进程用户态的栈顶指针,将sp减去sizeof(struct rt_sigframe)从而把该新建栈帧压入栈 - 调用
put_user_ex(),将sa_restorer按照函数栈的规则放到了frame->pretcode里面。函数栈里面包含了函数执行完跳回去的地址,当sa_handler执行完之后,弹出的函数栈是frame,也就应该跳到sa_restorer的地址 - 调用
setup_sigcontext()里面,将原来的pt_regs保存在了frame中的uc_mcontext里 - 填充
regs,将regs->ip设置为自定义的信号处理函数sa_handler,将栈顶regs->sp设置为新栈帧frame地址
1 | static int |
sa_restorer在__libc_sigaction()函数中被赋值为restore_rt,实际上调用函数调用__NR_rt_sigreturn()
1 | RESTORE (restore_rt, __NR_rt_sigreturn) |
__NR_rt_sigreturn()对应的内核函数为sys_rt_sigreturn(),这里会调用restore_sigframe()将pt_regs恢复成原进程的栈帧状态,从而继续执行函数调用后续的内容。
1 | asmlinkage int sys_rt_sigreturn(struct pt_regs *regs) |
总结
信号的发送与处理是一个复杂的过程,这里来总结一下。
- 假设我们有一个进程 A会从
tap网卡中读取数据,main函数里面调用系统调用通过中断陷入内核。 - 按照系统调用的原理,将用户态栈的信息保存在
pt_regs里面,也即记住原来用户态是运行到了 line A 的地方。 - 在内核中执行系统调用读取数据。
- 当发现没有什么数据可读取的时候进入睡眠状态,并且调用
schedule()让出 CPU。 - 将进程状态设置为可中断的睡眠状态
TASK_INTERRUPTIBLE,也即如果有信号来的话是可以唤醒它的。 - 其他的进程或者 shell 通过调用
kill()、tkill()、tgkill()、rt_sigqueueinfo()发送信号。四个发送信号的函数,在内核中最终都是调用do_send_sig_info()。 do_send_sig_info()调用send_signal()给进程 A 发送一个信号,其实就是找到进程 A 的task_struct,不可靠信号加入信号集合,可靠信号加入信号链表。do_send_sig_info()调用signal_wake_up()唤醒进程 A。- 进程 A 重新进入运行状态
TASK_RUNNING,接着schedule()运行。 - 进程 A 被唤醒后检查是否有信号到来,如果没有,重新循环到一开始,尝试再次读取数据,如果还是没有数据,再次进入
TASK_INTERRUPTIBLE,即可中断的睡眠状态。 - 当发现有信号到来的时候,就返回当前正在执行的系统调用,并返回一个错误表示系统调用被中断了。
- 系统调用返回的时候,会调用
exit_to_usermode_loop(),这是一个处理信号的时机。 - 调用
do_signal()开始处理信号。 - 根据信号得到信号处理函数
sa_handler,然后修改pt_regs中的用户态栈的信息让pt_regs指向sa_handler,同时修改用户态的栈,插入一个栈帧sa_restorer,里面保存了原来的指向 line A 的pt_regs,并且设置让sa_handler运行完毕后跳到sa_restorer运行。 - 返回用户态,由于
pt_regs已经设置为sa_handler,则返回用户态执行sa_handler。 sa_handler执行完毕后,信号处理函数就执行完了,接着会跳到sa_restorer运行。sa_restorer会调用系统调用rt_sigreturn再次进入内核。- 在内核中,
rt_sigreturn恢复原来的pt_regs,重新指向 line A。 - 从
rt_sigreturn返回用户态,还是调用exit_to_usermode_loop()。 - 这次因为
pt_regs已经指向 line A 了,于是就到了进程 A 中接着系统调用之后运行,当然这个系统调用返回的是它被中断了没有执行完的错误。
源码资料
[1] sigaction
[3] do_signal()
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统

