一. 前言
本文为进程间通信的最后一篇,介绍共享内存和信号量。之所以将二者一起叙述,是因为二者有着密不可分的关系。共享内存会利用虚拟内存和物理内存的映射关系,让不同进程开辟一块虚拟空间映射到相同的物理内存上,从而实现了两个进程对相同区域的读写,即进程间通信。而信号量则实现了互斥锁,可以为共享内存提供数据一致性的保证,因此二者常结合使用。
二. 基础知识
共享内存的使用包括
- 调用
shmget()创建共享内存 - 调用
shmat()映射共享内存至进程虚拟空间 - 调用
shmdt()接触映射关系
信号量有着类似的操作
- 调用
semget()创建信号量集合。 - 调用
semctl(),信号量往往代表某种资源的数量,如果用信号量做互斥,那往往将信号量设置为 1。 - 调用
semop()修改信号量数目,即加锁和解锁之用
整体通信过程可用如下生产者消费者的模式图来理解。
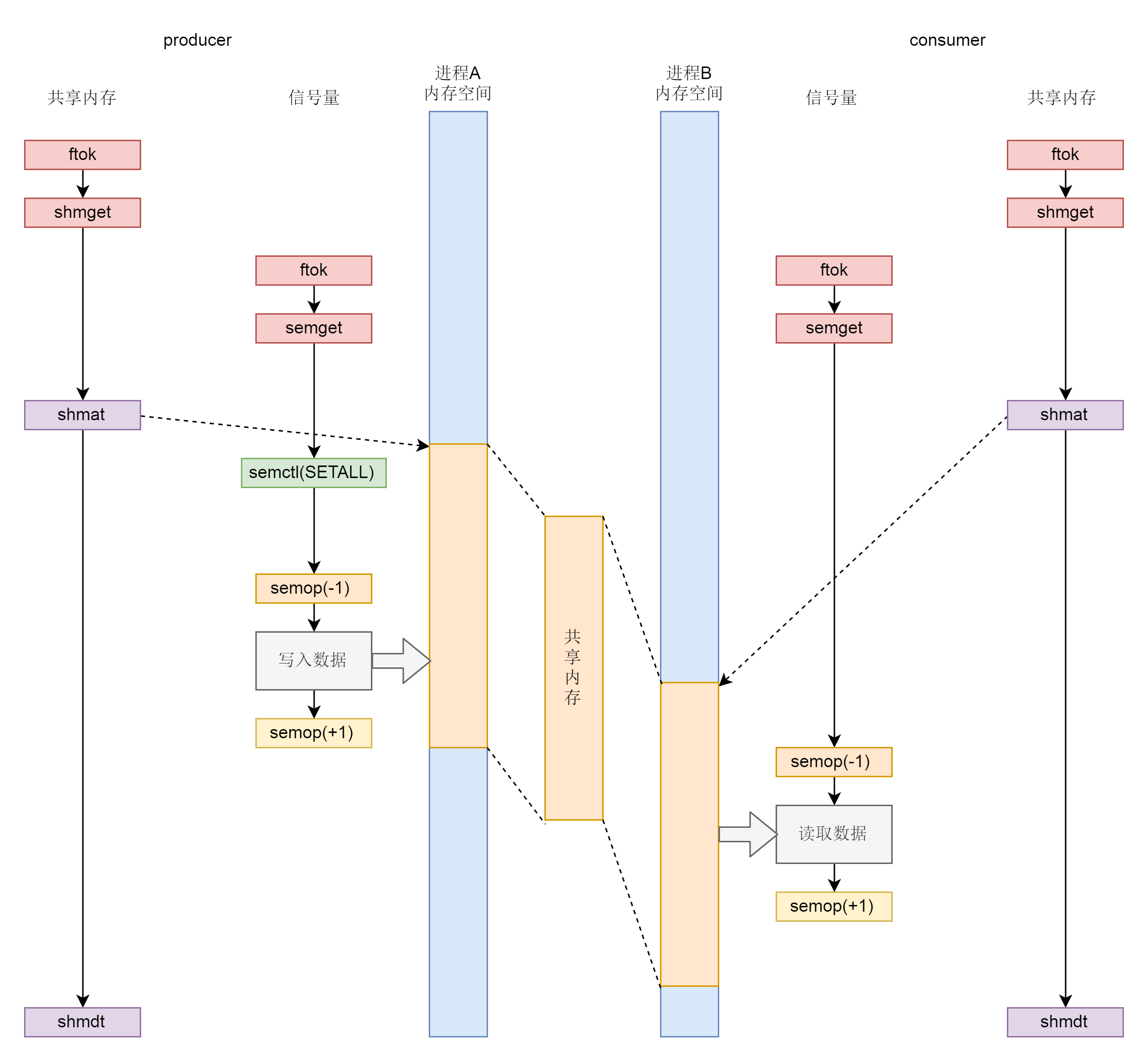
三. 统一封装的接口
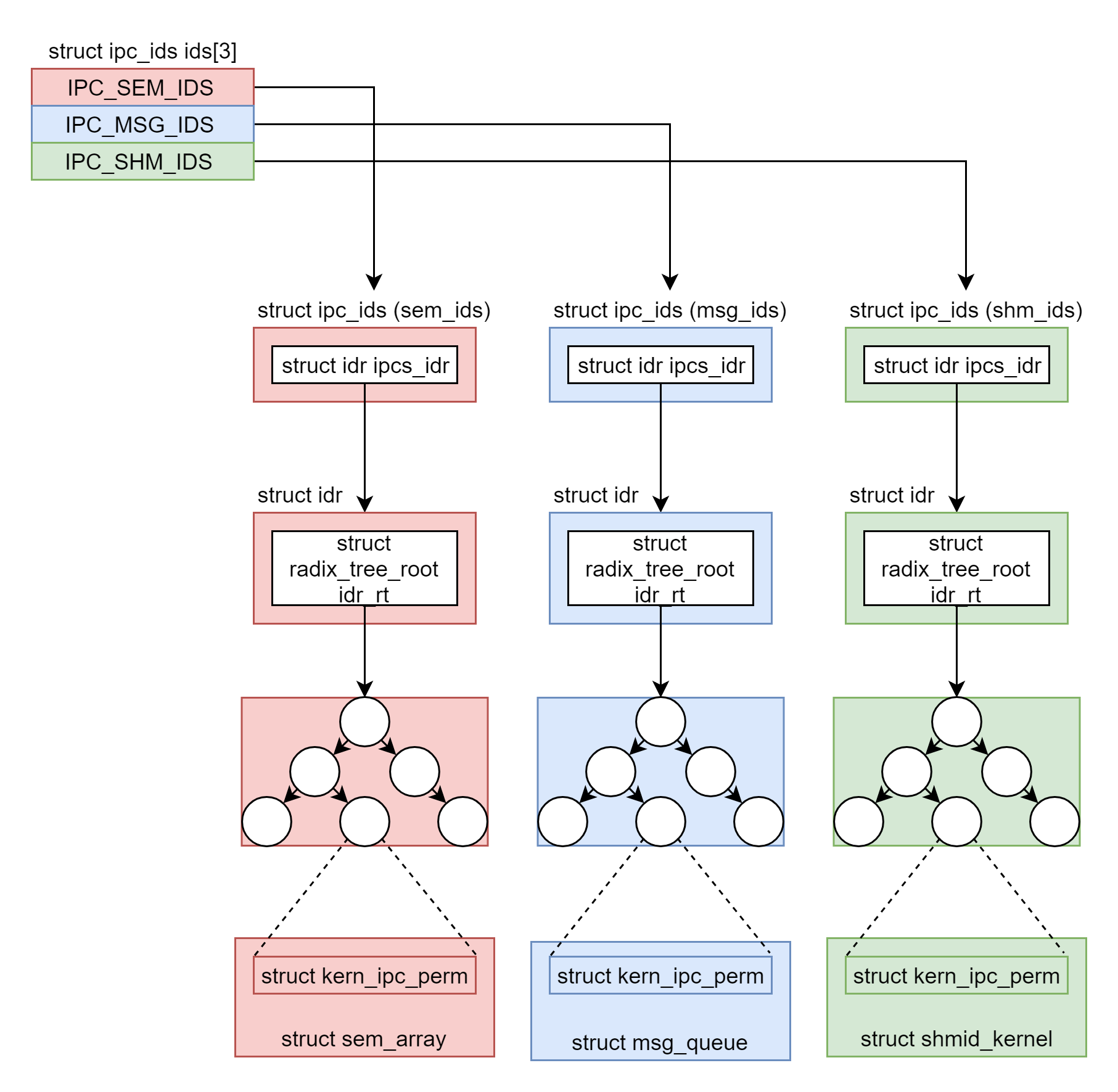
消息队列、共享内存和信号量有着统一的封装和管理机制,为此我们提供了对应的名字空间和ipc_ids结构体。根据代码中的定义,第 0 项用于信号量,第 1 项用于消息队列,第 2 项用于共享内存,分别可以通过 sem_ids、msg_ids、shm_ids 来访问。ipc_ids中in_use 表示当前有多少个 ipc,seq 和 next_id 用于一起生成 ipc 唯一的 id,ipcs_idr 是一棵基数树,一旦涉及从一个整数查找一个对象它都是最好的选择。
1 | struct ipc_namespace { |
信号量、消息队列、共享内存的通过基数树来管理各自的对象,三种ipc对应的结构体中第一项均为struct kern_ipc_perm,该结构体对应的id会存储在基数树之中,可以通过ipc_obtain_object_idr()获取。
1 | struct sem_array { |
对于这三种不同的通信方式,会对ipc_obtain_object_idr()进行封装
1 | static inline struct sem_array *sem_obtain_object(struct ipc_namespace *ns, int id) |
由此,我们实现了对这三种进程间通信方式统一的封装抽象。首先用名字空间存储三种ipc,然后对应的ipc_ids会描述该通信方式的特点,并包含一个基数树存储id从而找到其实际运行的多个通信的结构体。
四. 共享内存的创建和映射
4.1 创建共享内存
共享内存的创建通过shmget()实现。该函数创建对应的ipc_namespaace指针并指向该进程的ipc_ns,初始化共享内存对应的操作shm_ops,并将传参key, size, shmflg封装为传参shm_params,最终调用ipcget()。
1 | SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg) |
ipcget()会根据传参key的类型是否是IPC_PRIVATE选择调用ipcget_new()创建或者调用ipcget_public()打开对应的共享内存。
1 | int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids, |
ipcget_new()会根据定义的ops->getnew()创建新的ipc对象,即上面定义的newseg()。ipcget_public()会按照 key查找 struct kern_ipc_perm。如果没有找到,那就看是否设置了 IPC_CREAT,如果设置了,就调用ops->getnew()创建一个新的,否则返回错误ENOENT。如果找到了,就将对应的 id 返回。
1 | static int ipcget_new(struct ipc_namespace *ns, struct ipc_ids *ids, |
所以新的创建最后都会走到注册的newseg()函数。该函数主要逻辑为
- 通过
kvmalloc()在直接映射区分配一个struct shmid_kernel结构体,该结构体用于描述共享内存。 - 调用
hugetlb_file_setup()或shmem_kernel_file_setup()关联文件。虚拟地址空间可以和物理内存关联,但是页表的申请条件中会避开已分配的映射,即物理内存是某个进程独享的。所以如何实现物理内存向多个进程的虚拟内存映射呢?这里就要靠文件来实现了:虚拟地址空间也可以映射到一个文件,文件是可以跨进程共享的。这里我们并不是映射到硬盘上存储的文件,而是映射到内存文件系统上的文件。这里定要注意区分shmem和shm,前者是一个文件系统,后者是进程通信机制。 - 通过
ipc_addid()将新创建的struct shmid_kernel结构挂到shm_ids里面的基数树上,返回相应的id,并且将struct shmid_kernel挂到当前进程的sysvshm队列中。
1 | /** |
实际上shmem_kernel_file_setup()会在shmem文件系统里面创建一个文件:__shmem_file_setup() 会创建新的 shmem 文件对应的 dentry 和 inode,并将它们两个关联起来,然后分配一个 struct file 结构来表示新的 shmem 文件,并且指向独特的 shmem_file_operations。
1 | /** |
4.2 共享内存的映射
从上面的代码解析中我们知道,共享内存的数据结构 struct shmid_kernel通过它的成员 struct file *shm_file来管理内存文件系统 shmem 上的内存文件。无论这个共享内存是否被映射,shm_file 都是存在的。
对于用户来说,共享内存的映射通过调用shmat()完成。该函数主要逻辑为:
- 调用
shm_obtain_object_check()通过共享内存的id,在基数树中找到对应的struct shmid_kernel结构,通过它找到shmem上的内存文件base。 - 分配结构体
struct shm_file_data sfd表示该内存文件base。 - 创建
base的备份文件file,指向该内存文件base,并将private_data保存为sfd。在源码中注释部分已经叙述了为什么要再创建一个文件而不是直接使用base,简而言之就是base是共享内存文件系统shmem中的shm_file,用于管理内存文件,是一个中立、独立于任何一个进程的文件。新创建的struct file则专门用于做内存映射。 - 调用
do_mmap_pgoff(),分配vm_area_struct指向虚拟地址空间中未分配区域,其vm_file指向文件file,接着调用shm_file_operations中的mmap()函数,即shm_mmap()完成映射。
1 | SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg) |
shm_mmap() 中调用了 shm_file_data 中的 file 的 mmap() 函数,这次调用的是 shmem_file_operations 的 mmap,也即 shmem_mmap()。
1 | static int shm_mmap(struct file *file, struct vm_area_struct *vma) |
这里vm_area_struct 的 vm_ops 指向 shmem_vm_ops。等从 call_mmap() 中返回之后,shm_file_data 的 vm_ops 指向了 shmem_vm_ops,而 vm_area_struct 的 vm_ops 改为指向 shm_vm_ops。
1 | static const struct vm_operations_struct shm_vm_ops = { |
在前文内存映射中,我们提到了实际物理内存的分配不是在映射关系建立时就分配,而是当实际访问的时候通过缺页异常再进行分配。对于共享内存也是一样。当访问不到的时候,先调用 vm_area_struct 的 vm_ops,也即 shm_vm_ops 的 fault 函数 shm_fault()。然后它会转而调用 shm_file_data 的 vm_ops,也即 shmem_vm_ops 的 fault 函数 shmem_fault()。
shmem_fault() 会调用 shmem_getpage_gfp() 在 page cache 和 swap 中找一个空闲页,如果找不到就通过 shmem_alloc_and_acct_page() 分配一个新的页,他最终会调用内存管理系统的 alloc_page_vma 在物理内存中分配一个页。
1 | static int shm_fault(struct vm_fault *vmf) |
至此,共享内存才真的映射到了虚拟地址空间中,进程可以像访问本地内存一样访问共享内存。
五. 信号量的创建和使用
5.1 信号量的创建
信号量的创建和共享内存类似,实际调用semget(),操作也大同小异:创建对应的ipc_namespaace指针并指向该进程的ipc_ns,初始化共享内存对应的操作sem_ops,并将传参key, size, semflg封装为传参sem_params,最终调用ipcget()。
1 | SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg) |
共享内存最终走到newseg()函数,而信号量则调用newary(),该函数也有着类似的逻辑:
- 通过
kvmalloc()在直接映射区分配struct sem_array结构体描述该信号量。在该结构体中会有多个信号量保存在struct sem sems[]中,通过semval表示当前信号量。 - 初始化
sem_array和sems中的各个链表 - 通过
ipc_addid()将创建的sem_array挂载到基数树上,并返回对应id
1 | static int newary(struct ipc_namespace *ns, struct ipc_params *params) |
5.2 信号量的初始化
信号量通过semctl()实现初始化,主要使用semctl_main()和semctl_setval()函数。
1 | SYSCALL_DEFINE4(semctl, int, semid, int, semnum, int, cmd, unsigned long, arg) |
SETALL操作调用semctl_main(),传参为 union semun 里面的 unsigned short *array,会设置整个信号量集合。semctl_main() 函数中,先是通过 sem_obtain_object_check()根据信号量集合的 id 在基数树里面找到 struct sem_array 对象,发现如果是 SETALL 操作,就将用户的参数中的 unsigned short *array 通过 copy_from_user() 拷贝到内核里面的 sem_io 数组,然后是一个循环,对于信号量集合里面的每一个信号量,设置 semval,以及修改这个信号量值的 pid。
1 | static int semctl_main(struct ipc_namespace *ns, int semid, int semnum, |
SETVAL 操作调用semctl_setval()函数,传进来的参数 union semun 里面的 int val仅仅会设置某个信号量。在 semctl_setval() 函数中,我们先是通过 sem_obtain_object_check()根据信号量集合的 id 在基数树里面找到 struct sem_array 对象,对于 SETVAL 操作,直接根据参数中的 val 设置 semval,以及修改这个信号量值的 pid。
1 | static int semctl_setval(struct ipc_namespace *ns, int semid, int semnum, |
5.3 信号量的操作
信号量的操作通过semop()实现,实际调用sys_emtimedop(),最终调用为do_semtimedop()
1 | SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops, unsigned, nsops) |
do_semtimedop()是一个很较长的函数,逻辑比较复杂,主要为:
- 调用
copy_from_user()拷贝用户参数至内核态,如对信号量的操作struct sembuf。 - 如果需要进入等待状态,,则需要设置超时
- 调用
sem_obtain_object_check()根据id获取对应的信号量集合sma - 创建
struct sem_queue queue表示当前信号量操作。这里之所以称之为queue是因为操作的执行不可预期,因此排在队列之中等待信号量满足条件时再调用perform_atomic_semop()实施信号量操作。 - 如果不需要等待,则说明信号量操作已完成,也改变了信号量的值。接下来,就是一个标准流程。首先通过
DEFINE_WAKE_Q(wake_q)声明一个wake_q,调用do_smart_update()看这次对于信号量的值的改变可以影响并可以激活等待队列中的哪些struct sem_queue,然后把它们都放在wake_q里面,调用wake_up_q()唤醒这些进程。 - 如果需要等待,则会根据信号量操作是对单个信号量还是整个信号量集合,将
queue挂载至信号量链表pending_alter或者信号量集合的链表pending_alter中- 进入
do-while循环等待,如果没有时间限制则调用schedule()让出CPU资源,如果有则调用schedule_timeout()让出资源并过一段时间后回来。当回来的时候,判断是否等待超时,如果没有等待超时则进入下一轮循环,再次等待,如果超时则退出循环,返回错误。在让出CPU的时候,设置进程的状态为TASK_INTERRUPTIBLE,并且循环的结束会通过signal_pending查看是否收到过信号,这说明这个等待信号量的进程是可以被信号中断的,也即一个等待信号量的进程是可以通过 kill 杀掉的。
- 进入
1 | static long do_semtimedop(int semid, struct sembuf __user *tsops, |
do_smart_update() 会调用 update_queue(),update_queue() 会依次循环整个信号量集合的等待队列 pending_alter或者某个信号量的等待队列,试图在信号量的值变了的情况下,再次尝试 perform_atomic_semop 进行信号量操作。如果不成功,则尝试队列中的下一个;如果尝试成功,则调用 unlink_queue() 从队列上取下来,然后调用 wake_up_sem_queue_prepare()将 q->sleeper 加到 wake_q 上去。q->sleeper 是一个 task_struct,是等待在这个信号量操作上的进程。
1 | static int update_queue(struct sem_array *sma, int semnum, struct wake_q_head *wake_q) |
接下来wake_up_q 就依次唤醒 wake_q 上的所有 task_struct,调用的是进程调度中分析过的 wake_up_process()方法。
1 | void wake_up_q(struct wake_q_head *head) |
perform_atomic_semop() 函数对于所有信号量操作都进行两次循环。在第一次循环中,如果发现计算出的 result 小于 0,则说明必须等待,于是跳到 would_block 中,设置 q->blocking = sop 表示这个 queue 是 block 在这个操作上,然后如果需要等待,则返回 1。如果第一次循环中发现无需等待,则第二个循环实施所有的信号量操作,将信号量的值设置为新的值,并且返回 0。
1 | static int perform_atomic_semop(struct sem_array *sma, struct sem_queue *q) |
5.4 SEM_UNDO机制
信号量是整个 Linux 可见的全局资源,而不是某个进程独占的资源,好处是可以跨进程通信,坏处就是如果一个进程通过操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。为此,Linux设计了SEM_UNDO机制解决该问题。
该机制简而言之就是每一个 semop 操作都会保存一个反向 struct sem_undo 操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。在sem_flg标记位设置SUM_UNDO即可开启该功能。
1 | struct sem_queue { |
在进程的 task_struct 里面对于信号量有一个成员 struct sysv_sem,里面是一个 struct sem_undo_list将这个进程所有的 semop 所带来的 undo 操作都串起来。
1 | struct task_struct { |
这种设计思想较为常见,在MySQL的innodb的日志系统中也有着类似的实现。
总结
共享内存和信号量是有着相似性有可以共同使用从而完成进程通信的手段。下面引用极客时间中的两幅图来总结二者的整个过程。
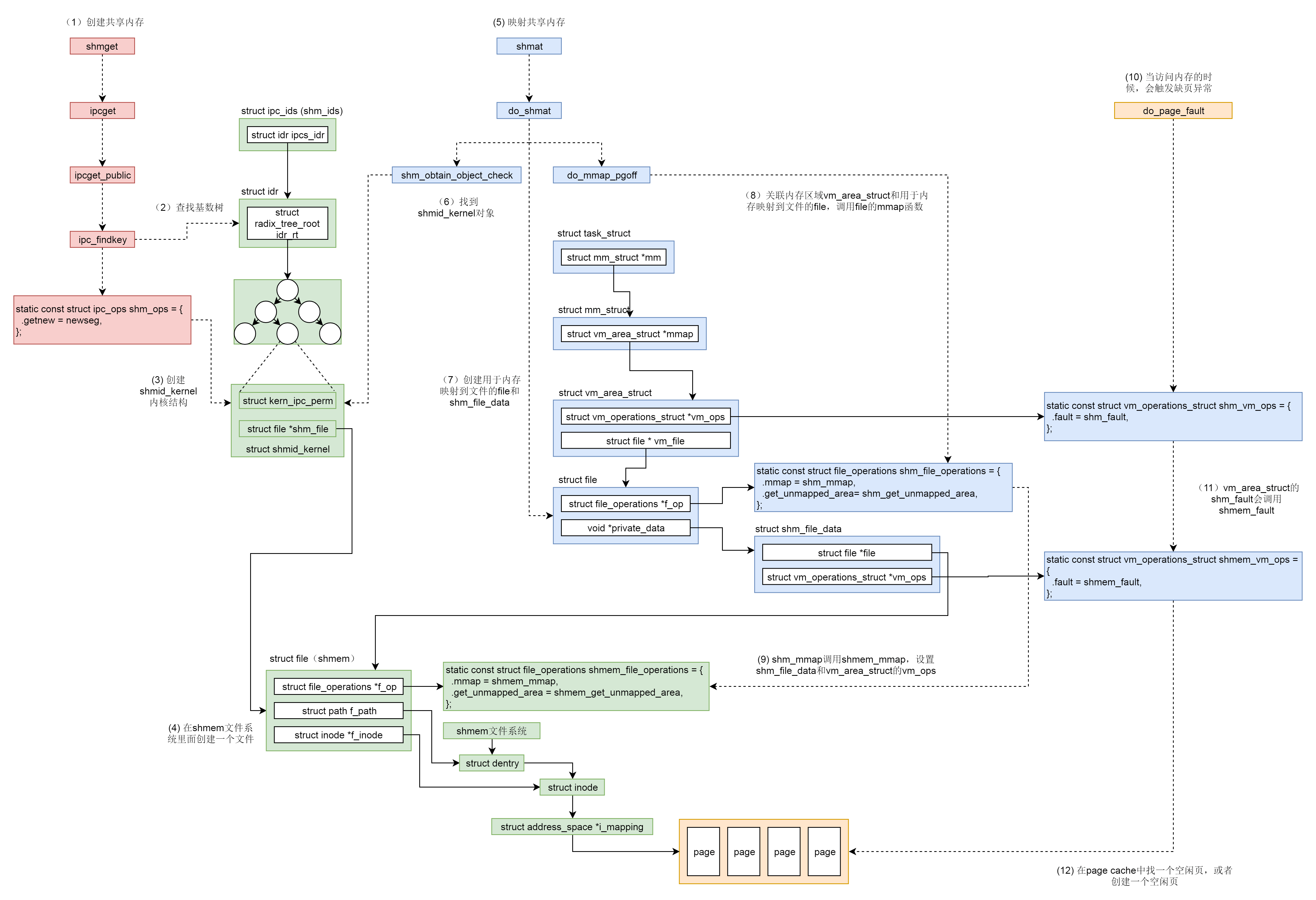
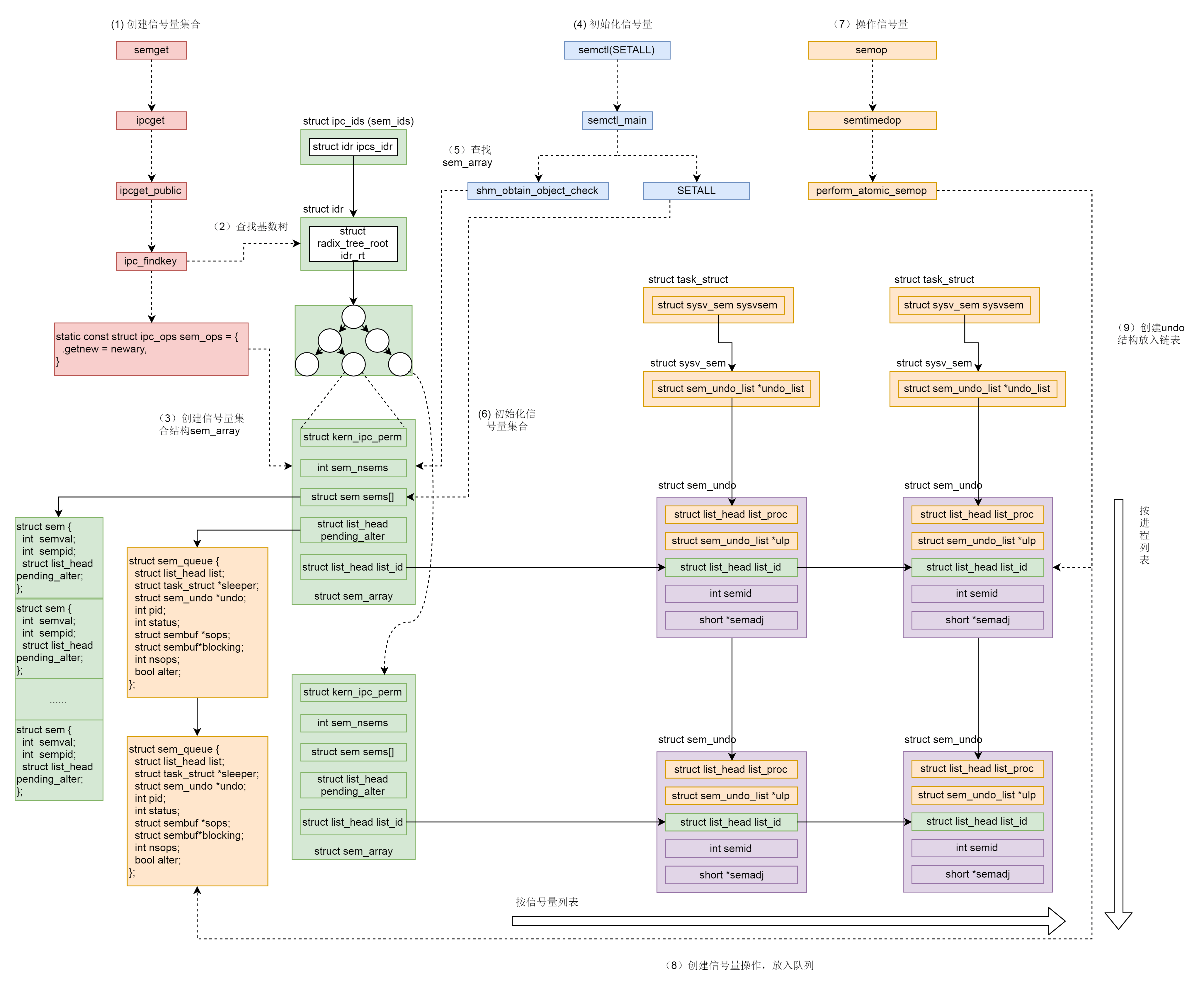
源码资料
[1] ipc_namespace
[2] ipc_get()
[3] newseg()
[4] do_shmat()
[5] shmem_fault()
[6] newary()
[7] semctl_main()
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统

