一. 前言
上文分析了内存再用户态的结构体mm_struct及各个区域映射的vm_area_struct以及32位和64位的内核态结构体,本文将基于这些结构来分析Linux的内存管理系统。内存管理系统包括虚拟内存和物理内存的分页以及虚拟内存和物理内存的映射。本文将介绍分页机制,而映射则在下文中说明。本文首先简单介绍SMP和NUMA系统,然后对物理内存的节点、区域、页结构进行分析,在此基础上剖析伙伴系统和Slub Allocator的实现原理,最后介绍页面交换。
二. 内存模型
在计算机的发展历程中,内存模型经历了平坦内存模型、SMP和NUMA三种架构。
- 平坦内存模型(Flat Memory Model),又称线性内存模型,在这种模式下,采取连续的物理地址和页,所以非常容易根据地址获取页号,反之亦然。此种布局非常简单,而且是线性增长,利于使用。但是随着内存需求的增大、进程数的变多、为了安全考虑,这种模型渐渐地无法满足要求。
- 对称多处理 SMP(Symmetric MultiProcessing),是一种多处理器的电脑硬件架构,在对称多处理架构下,每个处理器的地位都是平等的,对资源的使用权限相同。现代多数的多处理器系统都采用对称多处理架构。在这个系统中,拥有超过一个以上的处理器,这些处理器都连接到同一个共享的主存上,并由单一操作系统来控制。在对称多处理系统上,在操作系统的支持下,无论进程是处于用户空间,或是内核态,都可以分配到任何一个处理器上运行。因此,进程可以在不同的处理器间移动,达到负载平衡,使系统的效率提升。
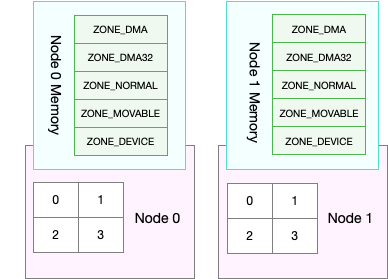
- 非均衡访存模型 NUMA(Non-Uniform Memory Access)。在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长。
三. 节点、区域和页
3.1 节点
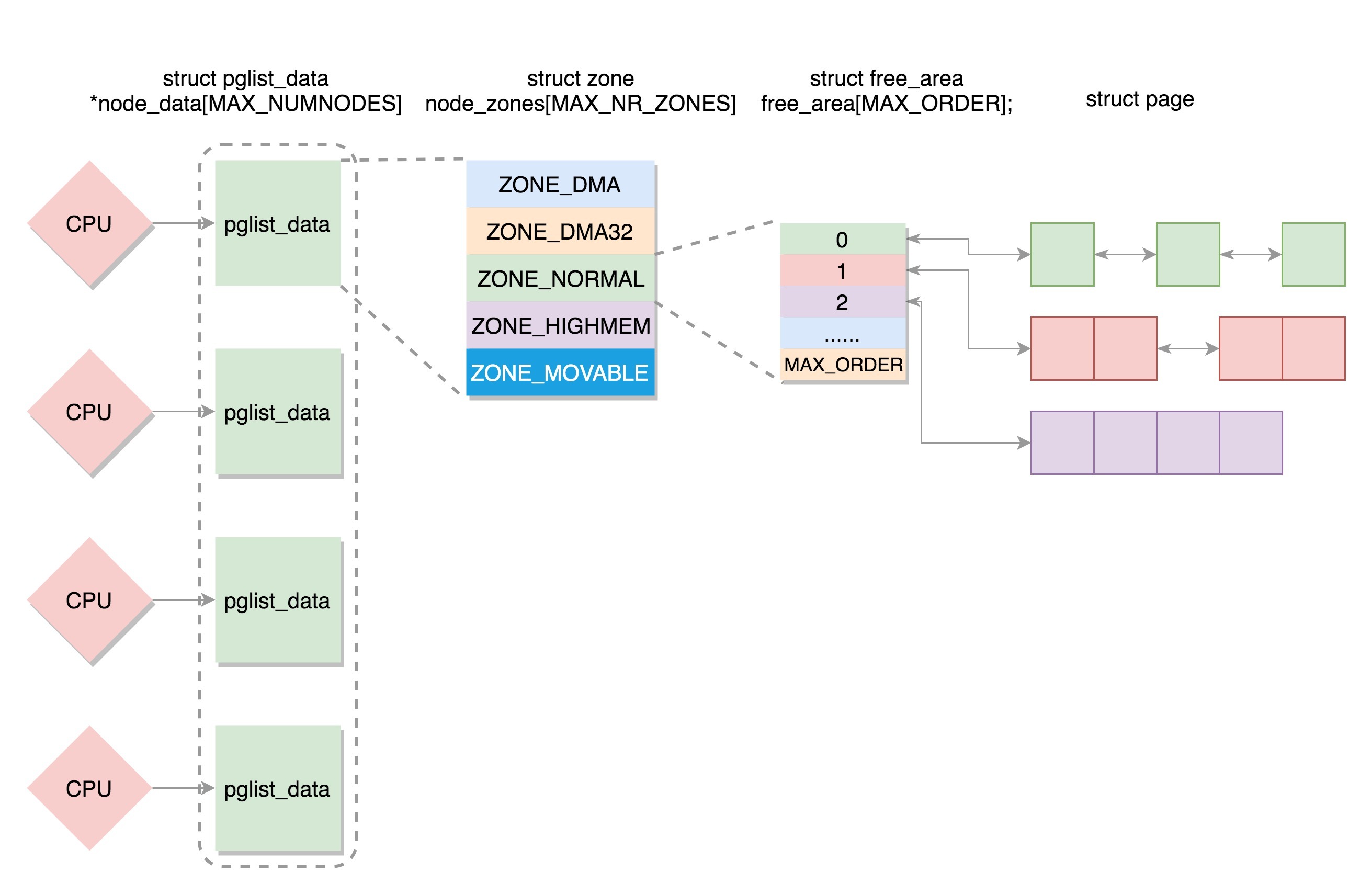
这里主要分析NUMA模型。我们将内存分为多个节点对应多个CPU,每个节点再被分成一个一个的区域,每个区域有多个页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,因此页号也就不再连续了。于是内存模型就变成了非连续内存模型。NUMA节点对应的结构为pglist_data,主要包括
- 节点ID
node_id - 节点区域相关:
node_zones,node_zonelists,nr_zones - 节点的页数组:
node_mam_map - 节点的起始页号:
node_start_pfn - 节点中包含不连续的物理内存地址页数:
node_spanned_pages - 可用的物理页面数目:
node_present_pates - 页面回收、交换相关:
kswapd_wait,kswapd,kswapd_order,kswapd_failures,kswapd_classzone_idx
1 | /* |
3.2 区域
每个节点可分成一个个的区域,node_zones存储了这些区域,node_zonelist以链表形式存储备用节点和它的内存区域的情况,nr_zones表示区域总数。区域的类型有如下几种,在上节中已简单提过,这里详细说明。
- ZONE_DMA 是指可用于作 DMA(Direct Memory Access,直接内存存取)的内存。DMA 是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。对于 64 位系统,有两个 DMA 区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32。
- ZONE_NORMAL 是直接映射区,即内核态前896M空间
- ZONE_HIGHMEM 是高端内存区,对于 32 位系统来说超过 896M 的地方,对于 64 位没必要有的一段区域。
- ZONE_MOVABLE 是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
1 |
|
区域的实现数据结构为zone,主要包括
- 区域初始页
zone_start_pfn - 区域总共跨多少页
spanned_pages - 区域在物理内存中真实存在的页数
present_pages - 区域被伙伴系统管理的所有页数
managed_pages - 冷热页区分
per_cpu_pagest:如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而per_cpu_pageset也是每个 CPU 一个。
1 | struct zone { |
3.3 页
每个区域有很多个页,现在让我们将目光投向页的结构page。页中使用了大量的联合,其原因在于页有着多种不同的使用方式。
- 整页使用方式。在前面介绍过,该种情况也存在两种页,一种是直接映射虚拟地址空间的匿名页(Anonymous Page),另一种则是用于关联文件、然后再和虚拟地址空间建立映射的页,称之为内存映射文件(Memory-mapped File)。对于该种模式,会使用联合里的以下变量
struct address_space *mapping:用于内存映射,如果是匿名页,最低位为 1;如果是映射文件,最低位为 0pgoff_t index:映射区的偏移量atomic_t _mapcount:指向该页的页表数struct list_head lru:表示这一页应该在一个链表上,例如这个页面被换出,就在换出页的链表中;compound相关的变量用于复合页(Compound Page),就是将物理上连续的两个或多个页看成一个独立的大页。
- 小块内存使用方式。在很多情况下,我们只需要使用少量内存,因此采用了slab allocator技术用于分配小块内存
slab。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态(状态包括:被分配了 / 被放回池子 / 应该被回收)。也正是因为slab allocator对于队列的维护过于复杂,后来就有了一种不使用队列的分配器slub allocator,但是里面还是用了很多 带有slab的API ,因为它保留了slab的用户接口,可以看成 slab allocator 的另一种实现。该种模式会使用联合里的以下变量s_mem:正在使用的 slab 的第一个对象freelist:池子中的空闲对象rcu_head:需要释放的列表
- 小块内存分配器slob,非常简单,常用于小型嵌入式系统
1 | struct page { |
四. 用户态页的分配
在上节中我们介绍了页按大小分配大致有伙伴系统和小块内存分配的slub分配。本节就这两种展开讨论。
4.1 伙伴系统
对于要分配比较大的内存,例如到分配页级别的,可以使用伙伴系统(Buddy System)。伙伴分配机制可以归纳如下。
- 采取多个链表将空闲页组织起来,每个链表中的节点包含的页块数目不同,即第
i个链表中的每个节点拥有2^i个页。 - 当向内核请求分配
(2^(i-1),2^i]数目的页块时,按照2^i页块请求处理,并将其分裂。 - 如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找,并对其进行分裂。如请求128个页,如果128页块链表无空闲则请求256链表,并将其分裂为两个128链表。
源码实现于alloc_pages()中,传参的定义如注释中所示,order表示分配2的order次方个页,gfp_mask表示分配区域,主要有
- GFP_USER:用于一个用户进程希望通过内存映射的方式访问某些硬件的缓存,例如显卡缓存
- GFP_KERNEL:用于内核中分配页,主要分配 ZONE_NORMAL 区域,也即直接映射区
- GFP_HIGHMEM:用于分配高端内存区域
- GFP_FS:用于文件映射区
- GFP_ATOMIC:表示该页内容不会进入休眠
这里涉及到了一种加快内存速度的技术:交叉存取技术(interleaved memory)。该存储方式会将存储体分为多个模块,每个模块类似于负载均衡逐个写入,这样当前字节被刷新时,可以不影响下一个字节的访问。交叉存储主要补偿DRAM等存储器相对较慢的读写速度。读或写每一个内存块,都需要等待内存块给出ready信号,才能读写下一字节。交叉存储将连续信息分散到各个块中,读写时可以同时等待多个内存块给出ready信号,从而提高了读写的速度。
1 | static inline struct page * |
交叉存取的alloc_page_interleave()函数实际上通过调用__alloc_page()最终也会调用__alloc_pages_nodemask()函数来实现分配。__alloc_pages_nodemask()是伙伴系统的核心方法,它会调用 get_page_from_freelist()在一个循环中轮询区域,先看当前节点的 zone,如果找不到空闲页则再看备用节点的 zone,直到找到为止。
1 | /* |
get_page_from_freelist()函数如下所示,主要调用rmqueue()找寻合适大小的队列,并取出页面。通过rmqueue()->__rmqueue()->__rmqueue_smallest()最终来到__rmqueue_smallest()函数
1 | /* |
在__rmqueue_smallest()中,实现了伙伴系统的找寻逻辑。从当前的order开始循环,如果page为空则order++,否则从当前链表lru中删除该页块,通过expand()函数将该区域剩余页块分配到其他对应的order链表中,最后返回该页块。
1 | /* |
expand()函数中将页块区域前移,size右移即除2,然后使用list_add加入链表之中
1 | /* |
最后以一张结构图作为总结
4.2 slub allocator
任务task_struct在派生时,会调用alloc_task_struct_node()分配task_struct对象,其底层调用kmem_cache_alloc_node()函数在task_struct的缓存区域kmem_cache *task_struct_cachep分配内存。在系统初始化的时候,task_struct_cachep 会被 kmem_cache_create() 函数创建。这个函数专门用于分配 task_struct 对象的缓存。这个缓存区的名字就叫 task_struct。
缓存区中每一块的大小正好等于 task_struct 的大小,也即 arch_task_struct_size。有了这个缓存区,每次创建 task_struct 的时候,先调用 kmem_cache_alloc_node()函数在缓存里面看看有没有直接可用的。当一个进程结束,task_struct 也不用直接被销毁,而是调用kmem_cache_free()放回到缓存中。这样,新进程创建的时候,我们就可以直接用现成的缓存中的 task_struct 了,从而加快了申请、释放速度。
1 | static struct kmem_cache *task_struct_cachep; |
下面分析一下缓冲区kmem_cache结构体。
kmem_cached_cpu和kmem_cached_node:每个NUMA节点都对应一个,分别是缓存分配的fast path和slow path。每次分配的时候,要先从kmem_cache_cpu进行分配。如果kmem_cache_cpu里面没有空闲的块,那就到kmem_cache_node中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。size,object_size和offset:通过链表list_head,所有的小内存块会联系起来存放在缓冲区,用于task_struct、mm_struct、fs_struct等申请小内存块,object_size表示某内存块的大小,size表示该内存块加上指针的总大小,offset表示下一个空闲内存块的指针的偏移量。
1 | /* |
首先来看看快分配方式kmem_cached_cpu,该结构体中page指向内存页块的第一页,freelist指向下一个可用的内存页块,partial表示部分被分配部分为空的页,该项为备用项,仅当page满了才会在partial中寻找,而partial本身指向的是kmem_cached_node中的partial链表。
1 | struct kmem_cache_cpu { |
kmem_cached_node结构体中也有类似的成员变量,但是相较之下会有更多详细信息,如slab链表总长度、空闲内存块的数量等等。
1 | /* |
下面回到缓冲区的分配函数kmem_cache_alloc_node()和释放函数kmem_cache_free。分配函数kmem_cache_alloc_node()实际调用slab_alloc_node()。从这里可以看出快通道和慢通道的处理逻辑。
- 快通道:尝试取出
kmem_cache_cpu cpu_slab的freelist,如果有空闲则返回,否则进入慢通道 - 慢通道:调用
__slab_alloc()分配新的内存块
1 | /* |
__slab_alloc()主要逻辑如下
- 在此尝试
kmem_cache_cpu中的freelist是否可用,因为当前进程可能被中断,等回到该进程继续执行时可能已经有了空闲内存块可以直接使用了,因此先检查一下 - 跳转到
new_slab标签,检查kmem_cache_cpu中的paritial,如果partial不为空则将kmem_cache_cpu中的page替换为partial,跳转至redo标签再次尝试分配 - 依然失败,则调用
new_slab_objects()分配新内存块
1 | /* |
new_slab_objects()函数逻辑如下
- 调用
get_partial()函数,根据node找到对应的kmem_cache_node然后调用get_partial_node()分配内存块。实际分配通过acquire_slab()函数完成,该函数会分配完成返回内存块指针并保存在freelist中,从kmem_cache_node的partial链表中拿下一大块内存来,并且将freelist,也就是第一块空闲的缓存块赋值给t。并且当第一轮循环的时候,将kmem_cache_cpu的page指向取下来的这一大块内存,返回的object就是这块内存里面的第一个缓存块t。如果kmem_cache_cpu也有一个partial,就会进行第二轮,再次取下一大块内存来,这次调用put_cpu_partial(),放到kmem_cache_cpu的partial里面。如果kmem_cache_node里面也没有空闲的内存,这就说明原来分配的页里面都放满了,执行下一步。 - 调用
new_slab()函数,向伙伴系统请求2^order个page,将请求的page构建成一个slab。分配的时候,要按kmem_cache_order_objects里面的order来。如果第一次分配不成功,说明内存已经很紧张了,那就换成 min 版本的kmem_cache_order_objects。其调用链为new_slab()->allocate_slab()->alloc_slab_page()->__alloc_pages_node()->__alloc_pages()->__alloc_pages_nodemask(),从这里回到了伙伴系统,可见上文对该函数的分析。
1 | static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags, |
至此,页的分配就介绍完了。简单概括就是伙伴系统将多个连续页面整合为页块以供大规模使用,slub allocator将从伙伴系统申请的大块切成小块,放在缓存,并分配给其他系统。物理内存分页之后,通过page_address()->lowmem_page_address()->page_to_virt()调用链转化为虚拟地址以使用。
五. 内核页表
内核态的页表在系统初始化的时候就需要创建,而非可以等到用的时候再创建页并映射。在 arch/x86/include/asm/pgtable_64.h有如下定义
1 | extern p4d_t level4_kernel_pgt[512]; |
其中swapper_pg_dir 指向内核最顶级的目录 pgd,同时出现的还有几个页表目录,其中 XXX_ident_pgt 对应的是直接映射区,XXX_kernel_pgt 对应的是内核代码区,XXX_fixmap_pgt 对应的是固定映射区。
初始化的位置位于arch\x86\kernel\head_64.S,以全局变量的方式保存。这里quad 表示声明了一项的内容,org表示跳到了某个位置。
init_top_pgt是内核页的顶级目录,首先将其指向level3_ident_pgt,即直接映射区页表的三级目录。前文中有说过直接映射区物理内存和虚拟内存通过减去偏移量实现,即__START_KERNEL_map,虚拟地址空间的内核代码段的起始地址。通过这种方式,我们得到了其对应的物理地址。接着我们通过PGD_PAGE_OFFSET偏移量和PGD_START_KERNEL偏移量进行两次跳转,其中PGD_PAGE_OFFSET对应__PAGE_OFFSET_BASE,即虚拟地址空间里面内核的起始地址。第二项则指向__START_KERNEL_map,即虚拟地址空间里面内核代码段的起始地址。其他代码也是同理,最终形成如下表所示的整个页表项的初始化工作。
1 | __INITDATA |
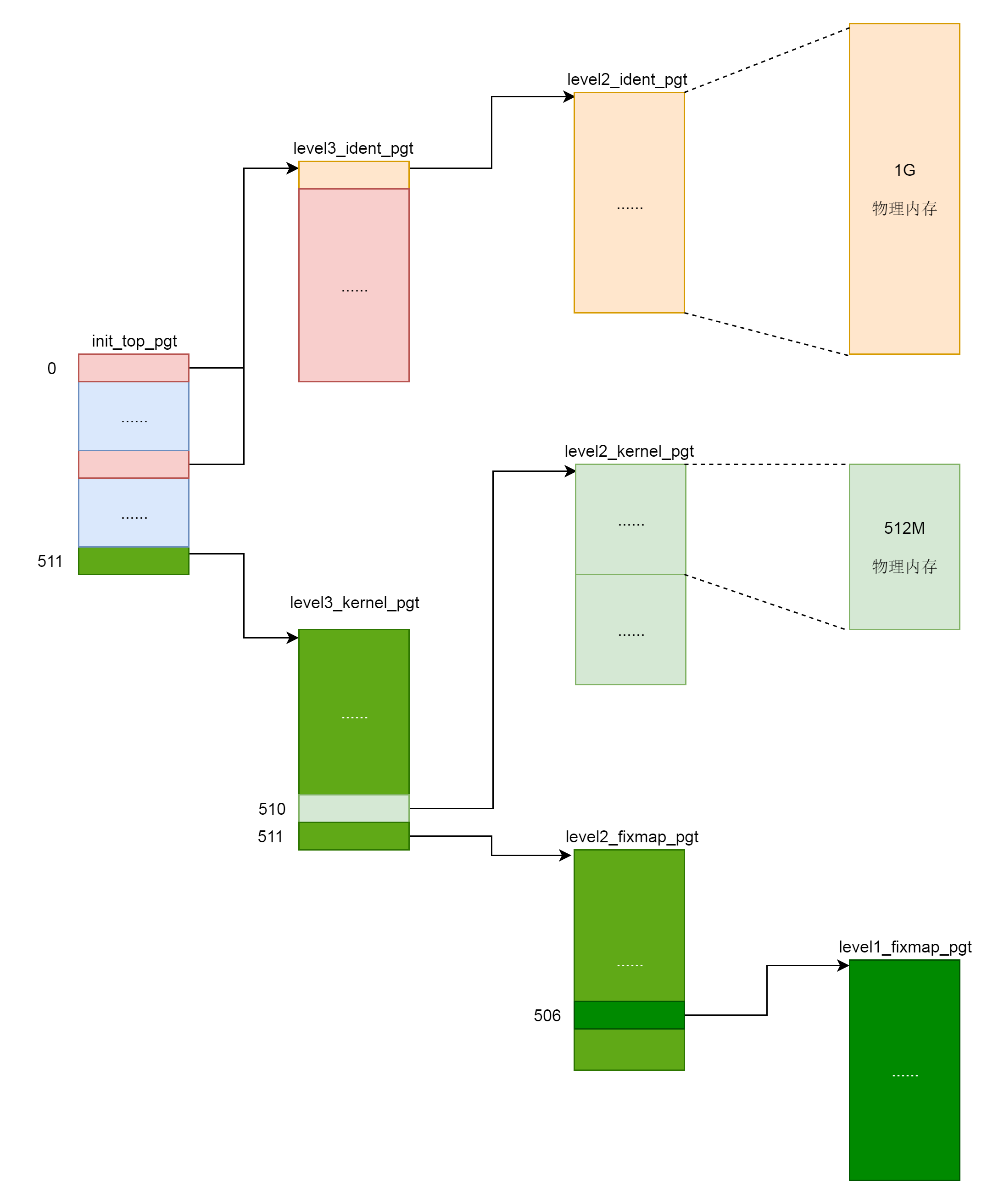
内核页表定义完了,一开始这里面的页表能够覆盖的内存范围比较小。例如内核代码区 512M,直接映射区 1G。这个时候,其实只要能够映射基本的内核代码和数据结构就可以了。可以看出里面还空着很多项,可以用于将来映射巨大的内核虚拟地址空间,等用到的时候再进行映射。如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir。
1 | struct mm_struct init_mm = { |
内核页表的初始化工作会在系统启动时,start_kernel()通过调用setup_arch()完成。load_cr3(swapper_pg_dir) 说明内核页表要开始起作用了,并且刷新了 TLB,初始化 init_mm 的成员变量,最重要的就是 init_mem_mapping(),通过调用链init_mem_mapping()->init_memory_mapping()->kernel_physical_mapping_init()最终通过 __va 将物理地址转换为虚拟地址,然后再创建虚拟地址和物理地址的映射页表。__va和__pa本身可以直接完成物理地址和虚拟地址的转换,但是CPU在保护模式下访问虚拟地址需要通过CR3寄存器,因此必须完成该映射页表的创建工作。
1 | void __init setup_arch(char **cmdline_p) |
六. 页面交换
由于虚拟内存是远大于物理内存的,在物理内存中加载所有的虚拟内存页显然是异想天开,因此我们必须要有页面的交换。和CPU调度相似,页的交换也包括主动的交换和被动的交换。
- 被动页面回收:当分配内存的时候发现物理内存不够用了,则尝试回收。如申请页面会调用
get_page_from_freelist(),该函数会通过调用链get_page_from_freelist()->node_reclaim()->__node_reclaim()->shrink_node()尝试是否可以对当前的内存节点执行换出操作,从而腾出空 - 主动页面管理:在内核中,内核线程
kswapd0即负责该部分的功能。下面详细展开分析一下该部分功能。
为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。

kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
1 | pages_low = pages_min*5/4 |
如下所示为kswapd()源码,核心调用链为balance_pgdat()->kswapd_shrink_node()->shrink_node(),所以被动回收和主动管理最后殊途同归,回到了同样的函数shrink_node()。
1 | /* |
shrink_node()实际调用shrink_node_memcg()。这里面有个 LRU 列表,所有的页面都被挂在 LRU 列表中。LRU 也就是最近最少使用。这个列表里面会按照活跃程度进行排序,这样就容易把不怎么用的内存页拿出来做处理。内存页总共分两类,一类是匿名页,和虚拟地址空间进行关联;一类是内存映射,不但和虚拟地址空间关联,还和文件管理关联。它们每一类都有两个列表,一个是 active,一个是 inactive。顾名思义,active 就是比较活跃的,inactive 就是不怎么活跃的。这两个里面的页会变化,过一段时间,活跃的可能变为不活跃,不活跃的可能变为活跃。如果要换出内存,那就是从不活跃的列表中找出最不活跃的,换出到硬盘上。
shrink_list() 会先缩减活跃页面列表,再压缩不活跃的页面列表。对于不活跃列表的缩减,shrink_inactive_list() 就需要对页面进行回收;对于匿名页来讲,需要分配 swap(),将内存页写入文件系统;对于内存映射关联了文件的,我们需要将在内存中对于文件的修改写回到文件中。
1 | /* |
六. 总结
内存管理可谓非常复杂,本文较为详尽的介绍了内存管理中分页和页的分配相关内容,下文将继续介绍物理内存和虚拟内存的映射。
源码资料
[1] pg_list_data
[2] page
[3] buddy system
[4] slub allocator
[6] kswapd
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统

