一. 前言
三次握手的基本知识在前文中已说明,本文从源码入手来详细分析其实现原理。
二. 基本过程和API
一个简单的TCP客户端/服务端模型如下所示,其中Socket()会创建套接字并返回描述符,在前文已经详细分析过。之后bind()会绑定本地的IP/Port二元组用以定位,而connect(), listen(), accept()则是本篇的重点所在,即通过三次握手完成连接的建立。
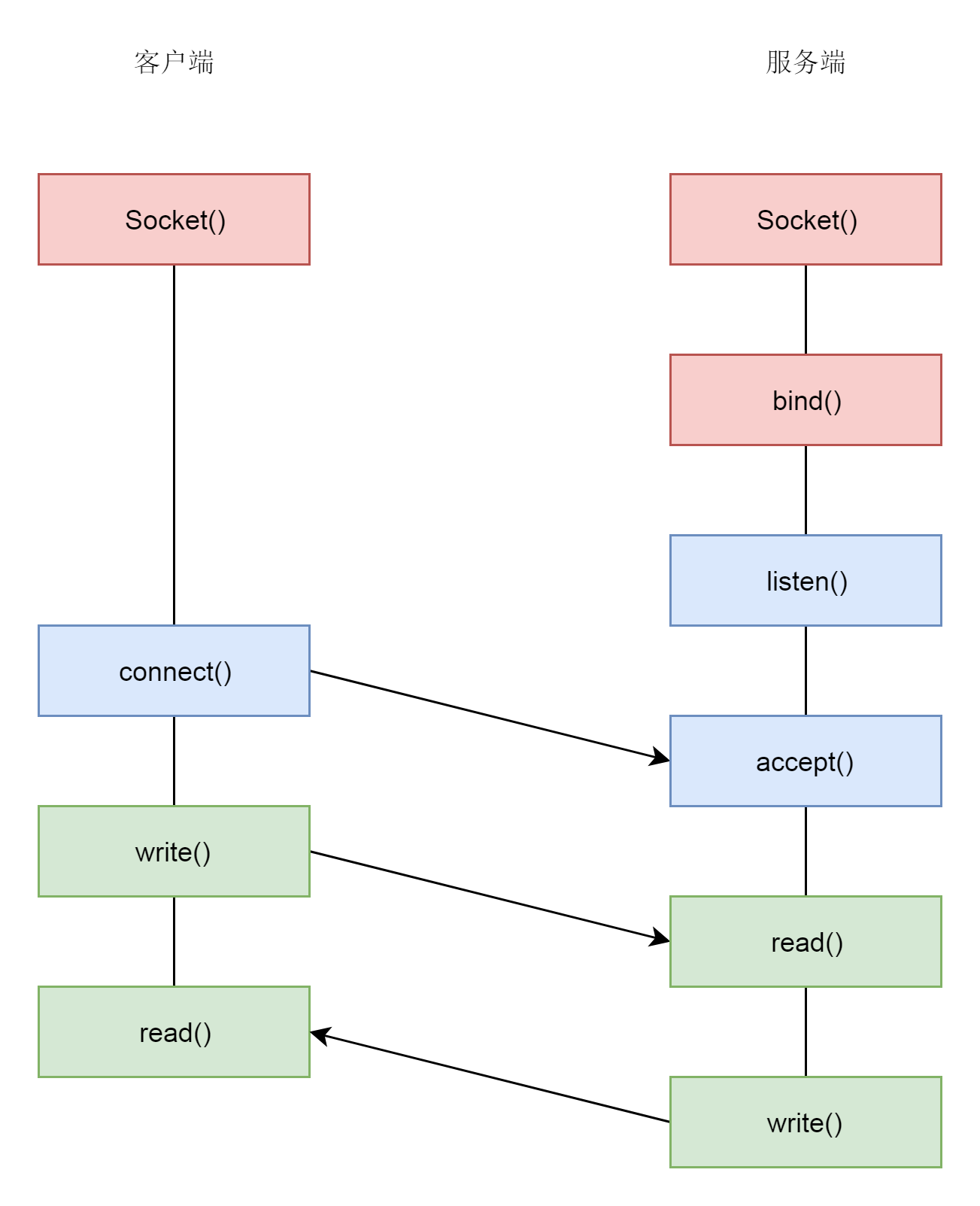
三. 源码分析
3.1 bind
首先来看看bind()函数。其API如下所示
1 | int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); |
该函数比较简单,主要是为套接字分配指定的IP地址及端口。在 bind() 中主要逻辑如下
- 调用
sockfd_lookup_light()根据fd文件描述符,找到 struct socket 结构 - 调用
move_addr_to_kernel()将sockaddr从用户态拷贝到内核态 - 调用
struct socket结构里面ops的bind()函数。根据前面创建socket的时候的设定,调用的是inet_stream_ops的bind()函数,也即调用inet_bind()。
1 | SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) |
sockfd_lookup_light()主要逻辑如下:
- 调用
fdget()->__fdget()->__fget_light()->__fcheck_files()获取文件file和flag组合成的结构体fd - 调用
sock_from_file()获取file对应的套接字sock
1 | static struct socket *sockfd_lookup_light(int fd, int *err, int *fput_needed) |
inet_bind()作用于网络层,因为传输层实际并无IP地址信息。主要逻辑为
- 调用
sk_prot的get_port()函数,也即inet_csk_get_port()来检查端口是否冲突,是否可以绑定。 - 如果允许,则会设置
struct inet_sock的本地地址inet_saddr和本地端口inet_sport,对方的地址inet_daddr和对方的端口inet_dport都初始化为 0。
1 | int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len) |
3.2 listen
listen()的API如下,其中backlog需要注意,其定义为套接字监听队列的最大长度,实际上会有个小坑,具体可见这篇博文分析。
1 | int listen(int sockfd, int backlog); |
其函数调用如下,主要逻辑为
- 调用
sockfd_lookup_light()查找套接字 - 根据
sysctl_somaxconn和backlog取较小值作为监听的队列上限 - 调用
ops的listen()函数,实际调用inet_stream_ops中的inet_listen()
1 | SYSCALL_DEFINE2(listen, int, fd, int, backlog) |
inet_listen()主要逻辑为判断套接字sock是否处于监听状态TCP_LISTEN,如果不是则调用inet_csk_listen_start()进入监听状态。
1 | int inet_listen(struct socket *sock, int backlog) |
inet_csk_listen_start()主要逻辑如下:
- 建立了一个新的结构
inet_connection_sock,这个结构一开始是struct inet_sock,inet_csk其实做了一次强制类型转换扩大了结构。struct inet_connection_sock结构比较复杂。如果打开它,你能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼。我们说 TCP 是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。 - 初始化
icsk_accept_queue队列。我们知道三次握手中有两个队列:半连接队列和全连接队列。其中半连接队列指三次握手还没完成,处于syn_rcvd的状态的连接,全连接指三次握手已经完毕,处于established状态的连接。icsk_accept_queue队列就是半连接队列,调用accept()函数时会从该队列取出连接进行判断,如果三次握手顺利完成则放入全连接队列。 - 将TCP状态设置为
TCP_LISTEN,调用get_port()确保端口可用。
1 | int inet_csk_listen_start(struct sock *sk, int backlog) |
3.3accept
accept()的API如下,服务端调用accept()会在监听套接字的基础上创建新的套接字来作为连接套接字,并返回连接套接字的描述符。
1 | int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); |
对应的系统调用如下,从这里可以很清楚的看到新套接字的创立,主要逻辑为:
- 调用
sockfd_lookup_light()查找描述符fd对应的监听套接字sock - 创建新套接字
newsock,类型和操作和监听套接字保持一致,并创建新的文件newfile和套接字绑定 - 调用套接字对应的
accept()函数,即inet_accept()完成实际服务端握手过程 - 调用
fd_install()关联套接字文件和套接字描述符,并返回连接的套接字描述符
1 | SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr, |
inet_accept()会提取监听套接字的网络层结构体sk1和新建套接字的sk2,调用sk1协议对应的accept()完成握手并保存连接状态于sk2中,这里实际调用的是inet_csk_accept()函数。接着将sk2和新建套接字进行关联。
1 | int inet_accept(struct socket *sock, struct socket *newsock, int flags, |
inet_csk_accept()函数会判断当前的半连接队列rskq_accept_queue是否为空,如果空则调用inet_csk_wait_for_connect()及逆行等待。如果不为空则从队列中取出一个连接,赋值给newsk并返回。
1 | struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) |
inet_csk_wait_for_connect()调用 schedule_timeout()让出 CPU,并且将进程状态设置为 TASK_INTERRUPTIBLE。如果再次 CPU 醒来,我们会接着判断 icsk_accept_queue 是否为空,同时也会调用 signal_pending 看有没有信号可以处理。一旦 icsk_accept_queue 不为空,就从 inet_csk_wait_for_connect() 中返回,在队列中取出一个 struct sock 对象赋值给 newsk。
1 | static int inet_csk_wait_for_connect(struct sock *sk, long timeo) |
3.4 connect
connect()函数通常由客户端发起,是三次握手的开始,服务端收到了SYN之后回复ACK + SYN并将该连接加入半连接队列,进入SYN_RCVD状态,第三次握手收到ACK后从半连接队列取出,加入全连接队列,此时的 socket 处于 ESTABLISHED 状态。accept()函数唤醒后检索队列,发现有连接则继续工作下去,从队列中取出该套接字并返回,供以后续读写使用。
1 | int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen); |
connect()对应的系统调用如下所示,其主要逻辑为:
- 调用
sockfd_lookup_light()查找套接字描述符fd对应的套接字sock - 调用
move_addr_to_kernel()将目的地址发到内核中供使用 - 调用初始化
connect()函数或者设置的特定connect()函数,这里会调用inet_stream_connect()发起连接
1 | SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, |
inet_stream_connect()主要逻辑为
- 判断当前套接字状态,如果尚未连接则调用
struct sock的sk->sk_prot->connect(),也即tcp_prot的connect()函数tcp_v4_connect()函数发起握手。 - 调用
inet_wait_for_connect(),等待来自于服务端的ACK信号
1 | int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, |
tcp_v4_connect()主要逻辑为
- 调用
ip_route_connect()选择一条路由,根据选定的网卡填写该网卡的 IP 地址作为源IP地址 - 将客户端状态设置为
TCP_SYN_SENT,初始化序列号write_seq - 调用
tcp_connect()发送SYN包
1 | int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) |
tcp_connect()主要逻辑为
- 创建新的结构体
struct tcp_sock该结构体是struct inet_connection_sock的一个扩展,维护了更多的 TCP 的状态 - 调用
tcp_init_nondata_skb()初始化一个SYN包 - 调用
tcp_transmit_skb()将SYN包发送出去 - 调用
inet_csk_reset_xmit_timer()设置了一个timer,如果SYN发送不成功,则再次发送。
1 | int tcp_connect(struct sock *sk) |
关于底层发包收包留到后面单独解析,这里先重点看三次握手的过程。当发包完成后,我们会等待接收ACK,接收数据包的调用链为tcp_v4_rcv()->tcp_v4_do_rcv()->tcp_rcv_state_process()。tcp_rcv_state_process()是一个服务端客户端通用函数,根据状态位来判断如何执行。
- 当服务端处于
TCP_LISTEN状态时,收到第一次握手即客户端的SYN,调用conn_request()进行处理,其实调用的是tcp_v4_conn_request(),更新自身状态、队列,然后调用tcp_v4_send_synack()发送第二次握手消息,进入状态TCP_SYN_RECV - 当客户端处于
TCP_SYN_SENT状态时,收到服务端返回的第二次握手消息ACK + SYN,调用tcp_rcv_synsent_state_process()进行处理,调用tcp_send_ack()发送ACK回复给服务端,进入TCP_ESTABLISHED状态 - 服务端处于
TCP_SYN_RECV状态时,收到客户端返回的第三次握手消息ACK,进入TCP_ESTABLISHED状态
1 | int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) |
总结
本文较为详细的叙述了三次握手的整个过程,四次挥手有着类似的过程因此不做赘述,其中的区别在于多了一个TIME_WAIT以及对应的定时器。下篇文章开始我们将详细分析发包和收包的整个网络协议栈流程。
源码资料
[1] bind()
[2] inet_bind()
[3] listen()
[4] inet_listen()
[5] accept()
[6] inet_accept()
[7] connect()
[9] tcp_v4_connect()
[10] tcp_conn_request()
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统
[8] 深入理解Linux网络技术内幕

