一. 前言
本节开始将分析Linux的文件系统。Linux一切皆文件的思想可谓众所周知,而其文件系统又是字符设备、块设备、管道、进程间通信、网络等等的必备知识,因此其重要性可想而知。本文将先介绍文件系统基础知识,然后介绍最重要的结构体inode以及构建于其上的一层层的文件系统。
二. 文件系统基础知识
一切设计均是为了实现需求,因此我们从文件系统需要的基本功能来看看其该如何设计。首先,一个文件系统需要有以下基本要求
- 文件需要让人易于读写,并避免名字冲突等
- 文件需要易于查找、整理归类
- 操作系统需要有文档记录功能以便管理
由此,文件系统设计了如下特性
- 采取树形结构、文件夹设计
- 对热点文件进行缓存,便于读写
- 采用索引结构,便于查找分类
- 维护一套数据结构用于记录哪些文档正在被哪些任务使用
依此基本设计,我们可以开始慢慢展开看看Linux博大而精神的文件系统。
三. inode结构体和文件系统
3.1 块存储的表示
硬盘中我们以块为存储单元,而在文件系统中,我们需要有一个存储块信息的基本结构体,这就是文件系统的基石inode,其源码如下。inode意为index node,即索引节点。从这个数据结构中我们可以看出,inode 里面有文件的读写权限 i_mode,属于哪个用户 i_uid,哪个组 i_gid,大小是多少 i_size_lo,占用多少个块 i_blocks_lo。另外,这里面还有几个与文件相关的时间。i_atime 即 access time,是最近一次访问文件的时间;i_ctime 即 change time,是最近一次更改 inode 的时间;i_mtime 即 modify time,是最近一次更改文件的时间。
1 | /* |
这里我们需要重点关注以下i_block,该成员变量实际存储了文件内容的每一个块。在ext2和ext3格式的文件系统中,我们用前12个块存放对应的文件数据,每个块4KB,如果文件较大放不下,则需要使用后面几个间接存储块来保存数据,下图很形象的表示了其存储原理。
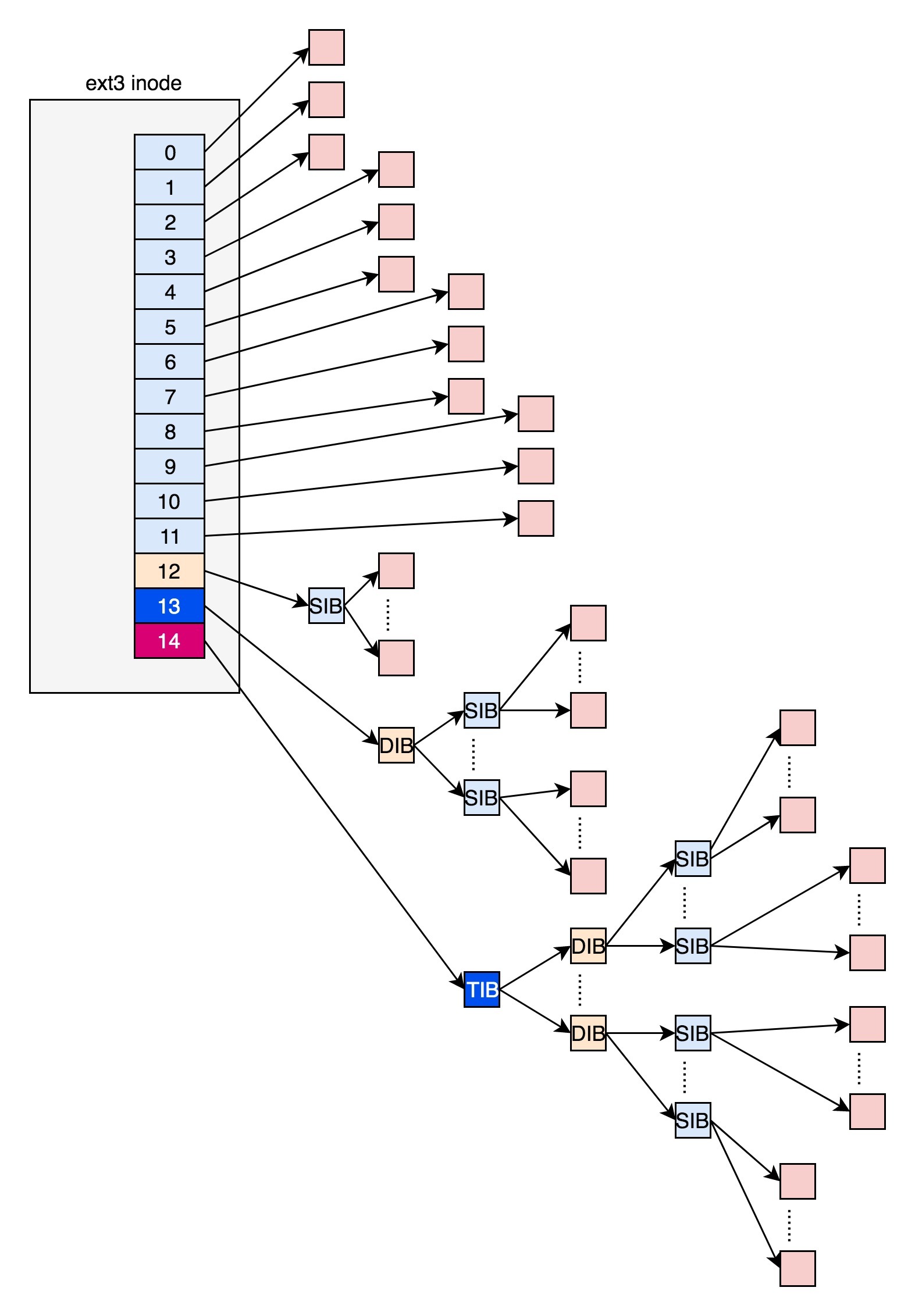
该存储结构带来的问题是对于大型文件,我们需要多次调用才可以访问对应块的内容,因此访问速度较慢。为此,ext4提出了新的解决方案:Extents。简单的说,Extents以一个树形结构来连续存储文件块,从而提高访问速度,大致结构如下图所示。

主要结构体为节点ext4_extent_header,eh_entries 表示这个节点里面有多少项。这里的项分两种:
- 如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点
ext4_extent; - 如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点
ext4_extent_idx。这两种类型的项的大小都是 12 个byte。
如果文件不大,inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。所以这个时候,eh_depth 为 0,也即 inode 里面的就是叶子节点,树高度为 0。如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树,eh_depth>0 的节点就是索引节点,其中根节点深度最大,在 inode 中。最底层 eh_depth=0 的是叶子节点。除了根节点,其他的节点都保存在一个块 4k 里面,4k 扣除 ext4_extent_header 的 12 个 byte,剩下的能够放 340 项,每个 extent 最大能表示 128MB 的数据,340 个 extent 会使你表示的文件达到 42.5GB。这已经非常大了,如果再大,我们可以增加树的深度。
1 | /* |
由此,我们可以通过inode来表示一系列的块,从而构成了一个文件。在硬盘上,通过一系列的inode,我们可以存储大量的文件。但是我们尚需要一种方式去存储和管理inode,这就是位图。同样的,我们会用块位图去管理块的信息。如下所示为创建inode的过程中对位图的访问,我们需要找出下一个0位所在,即空闲inode的位置。
1 | struct inode *__ext4_new_inode(handle_t *handle, struct inode *dir, |
3.2 文件系统的格式
inode和块是文件系统的最小组成单元,在此之上还有多级系统,大致有如下这些:
- 块组:存储一块数据的组成单元,数据结构为
ext4_group_desc。这里面对于一个块组里的inode位图bg_inode_bitmap_lo、块位图bg_block_bitmap_lo、inode列表bg_inode_table_lo均有相应的定义。一个个块组,就基本构成了我们整个文件系统的结构。 - 块组描述符表:多个块组的描述符构成的表
- 超级块:对整个文件系统的情况进行描述,即
ext4_super_block,存储全局信息,如整个文件系统一共有多少inode:s_inodes_count;一共有多少块:s_blocks_count_lo,每个块组有多少inode:s_inodes_per_group,每个块组有多少块:s_blocks_per_group等。 - 引导块:对于整个文件系统,我们需要预留一块区域作为引导区用于操作系统的启动,所以第一个块组的前面要留 1K,用于启动引导区。
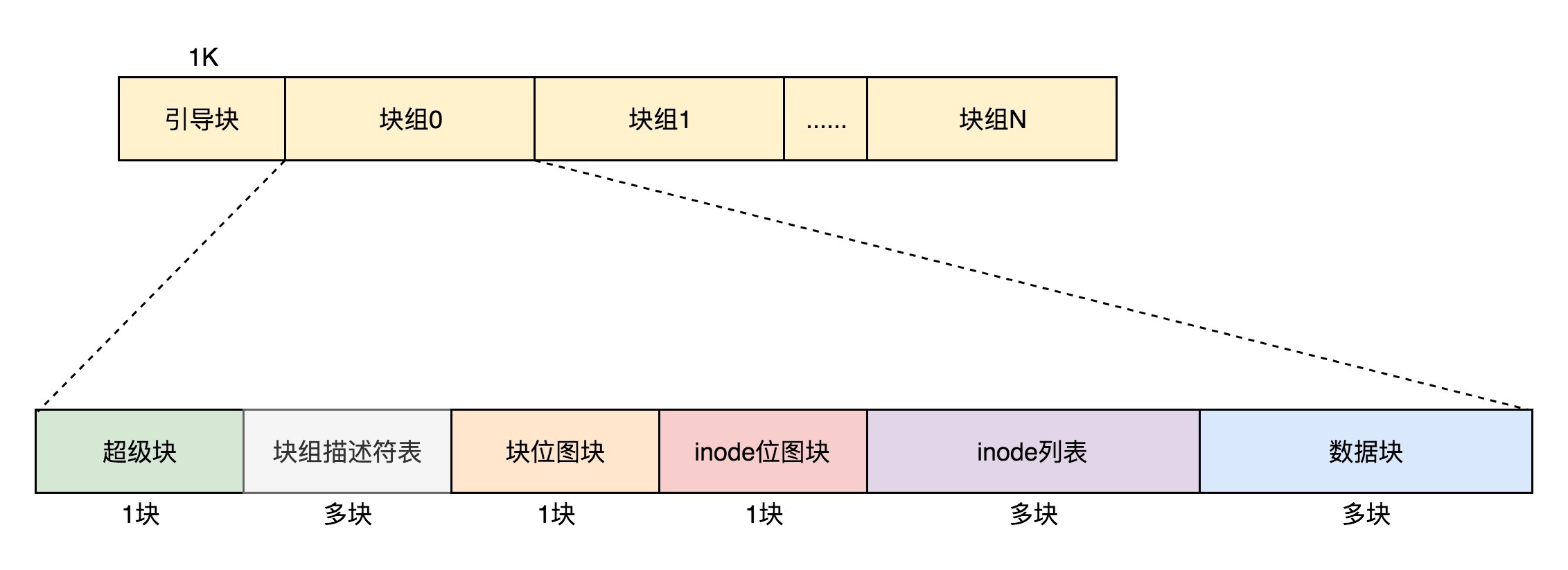
超级块和块组描述符表都是全局信息,而且这些数据很重要。如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。
- 默认策略:在每个块中均保存一份超级块和块组描述表的备份
- sparse_super策略:采取稀疏存储的方式,仅在块组索引为 0、3、5、7 的整数幂里存储。
- Meta Block Groups策略:我们将块组分为多个元块组(Meta Block Groups),每个元块组里面的块组描述符表仅仅包括自己的内容,一个元块组包含 64 个块组,这样一个元块组中的块组描述符表最多 64 项。这种做法类似于
merkle tree,可以在很大程度上优化空间。
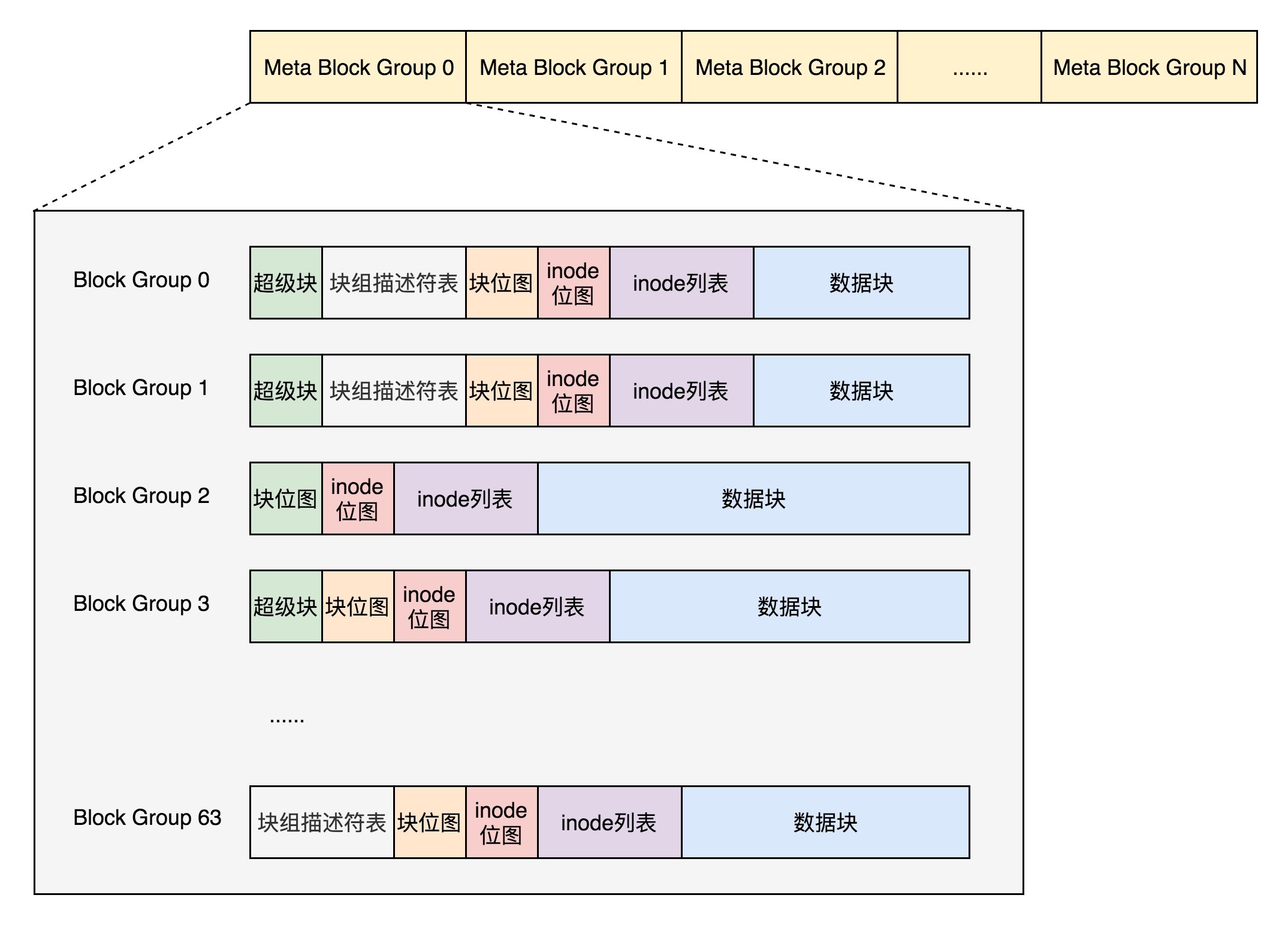
3.3 目录的存储格式
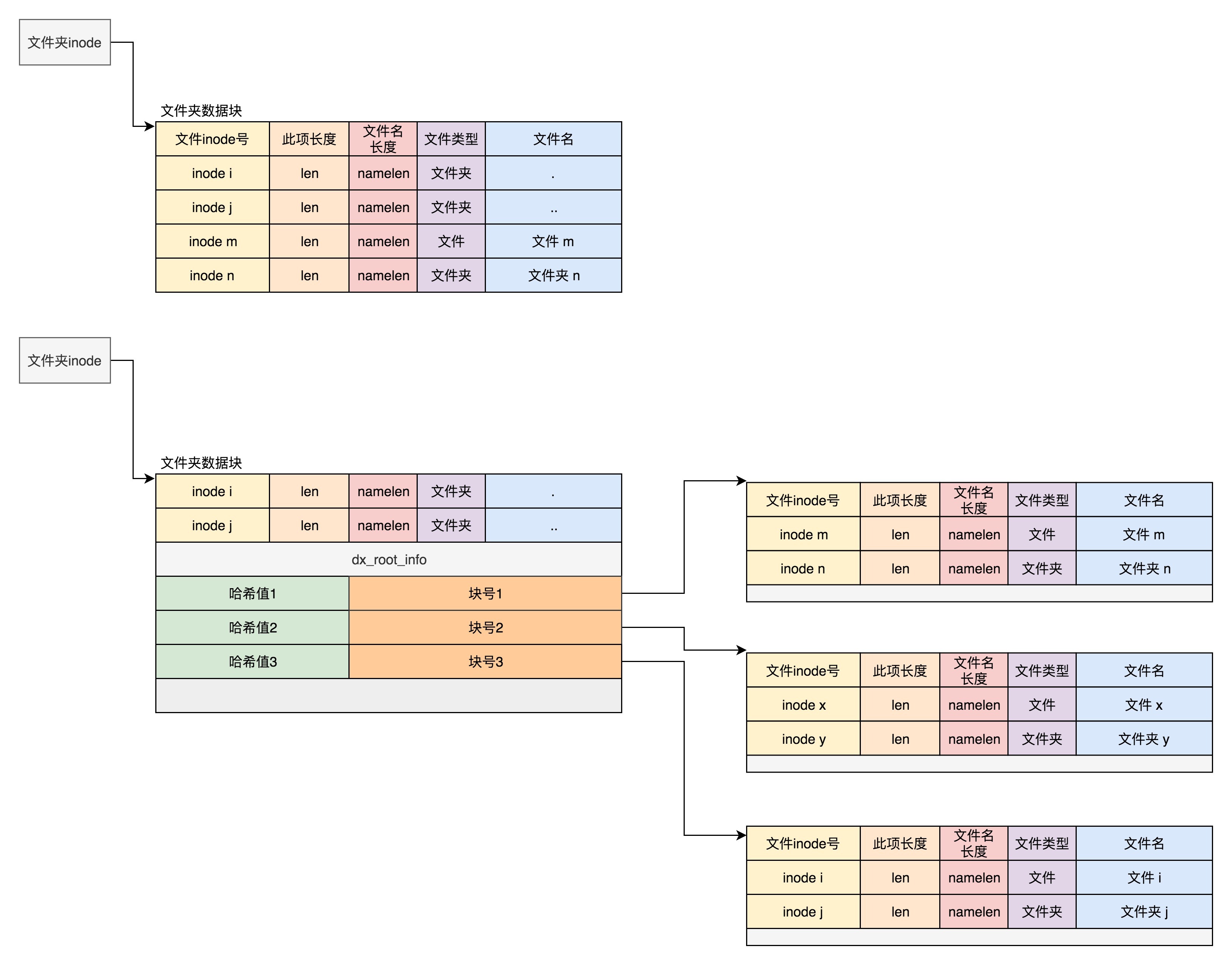
为了便于文件的查找,我们必须要有索引,即文件目录。其实目录本身也是个文件,也有 inode。inode 里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为 ext4_dir_entry。这里有两个版本,第二个版本 ext4_dir_entry_2 是将一个 16 位的 name_len,变成了一个 8 位的 name_len 和 8 位的 file_type。
1 | struct ext4_dir_entry { |
在目录文件的块中,最简单的保存格式是列表,就是一项一项地将 ext4_dir_entry_2 列在哪里。每一项都会保存这个目录的下一级的文件的文件名和对应的 inode,通过这个 inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和 inode。有时候,如果一个目录下面的文件太多的时候,我们想在这个目录下找一个文件,按照列表一个个去找太慢了,于是我们就添加了索引的模式。如果在 inode 中设置 EXT4_INDEX_FL 标志,则目录文件的块的组织形式将发生变化,变成了下面定义的这个样子:
1 | struct dx_root |
当前目录和上级目录不变,文件列表改用dx_root_info结构体,其中最重要的成员变量是 indirect_levels,表示间接索引的层数。索引项由结构体 dx_entry表示,本质上是文件名的哈希值和数据块的一个映射关系。
1 | struct dx_entry |
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是 ext4_dir_entry_2 的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的 N 多的文件分散到很多的块里面,可以很快地进行查找。
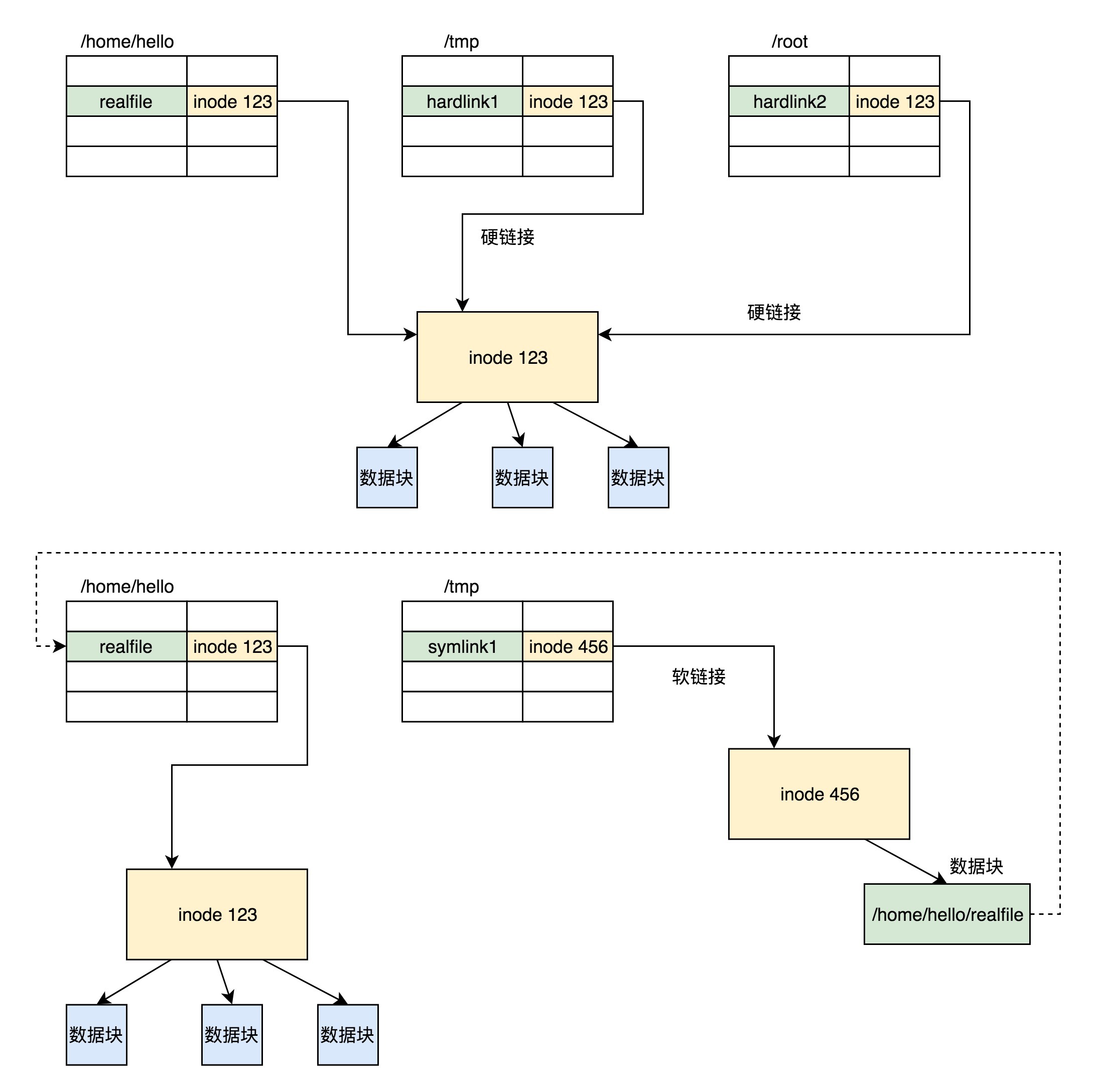
3.4 软链接和硬链接的存储格式
软链接和硬链接也是文件的一种,可以通过如下命令创建。ln -s 创建的是软链接,不带 -s 创建的是硬链接。
1 | ln [参数][源文件或目录][目标文件或目录] |
硬链接与原始文件共用一个 inode ,但是 inode 是不跨文件系统的,每个文件系统都有自己的 inode 列表,因而硬链接是没有办法跨文件系统的。而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的 inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了链接文件也依然存在,只不过指向的文件找不到了而已。
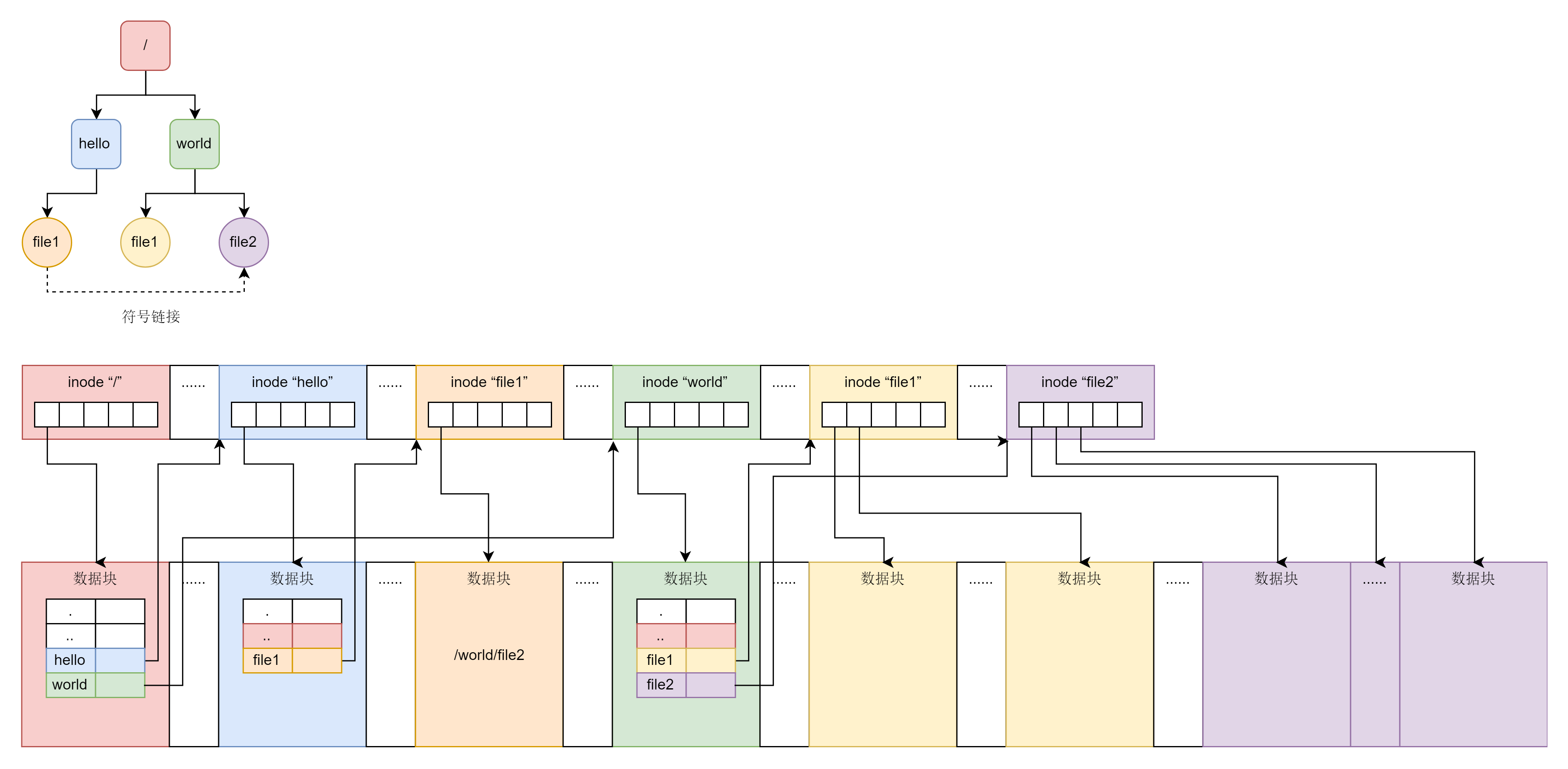
四. 总结
本文主要从文件系统的设计角度出发,逐步分析了inode和基于inode的ext4文件系统结构和主要组成部分,下面引用极客时间中的一张图作为总结。
源码资料
[1] inode
[2] ext4_inode
[3] ext4_extent
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统

