一. 前言
本文是性能优化系列的最后一篇,将分析磁盘I/O的性能指标、测试方法、常见问题的优化套路等内容。
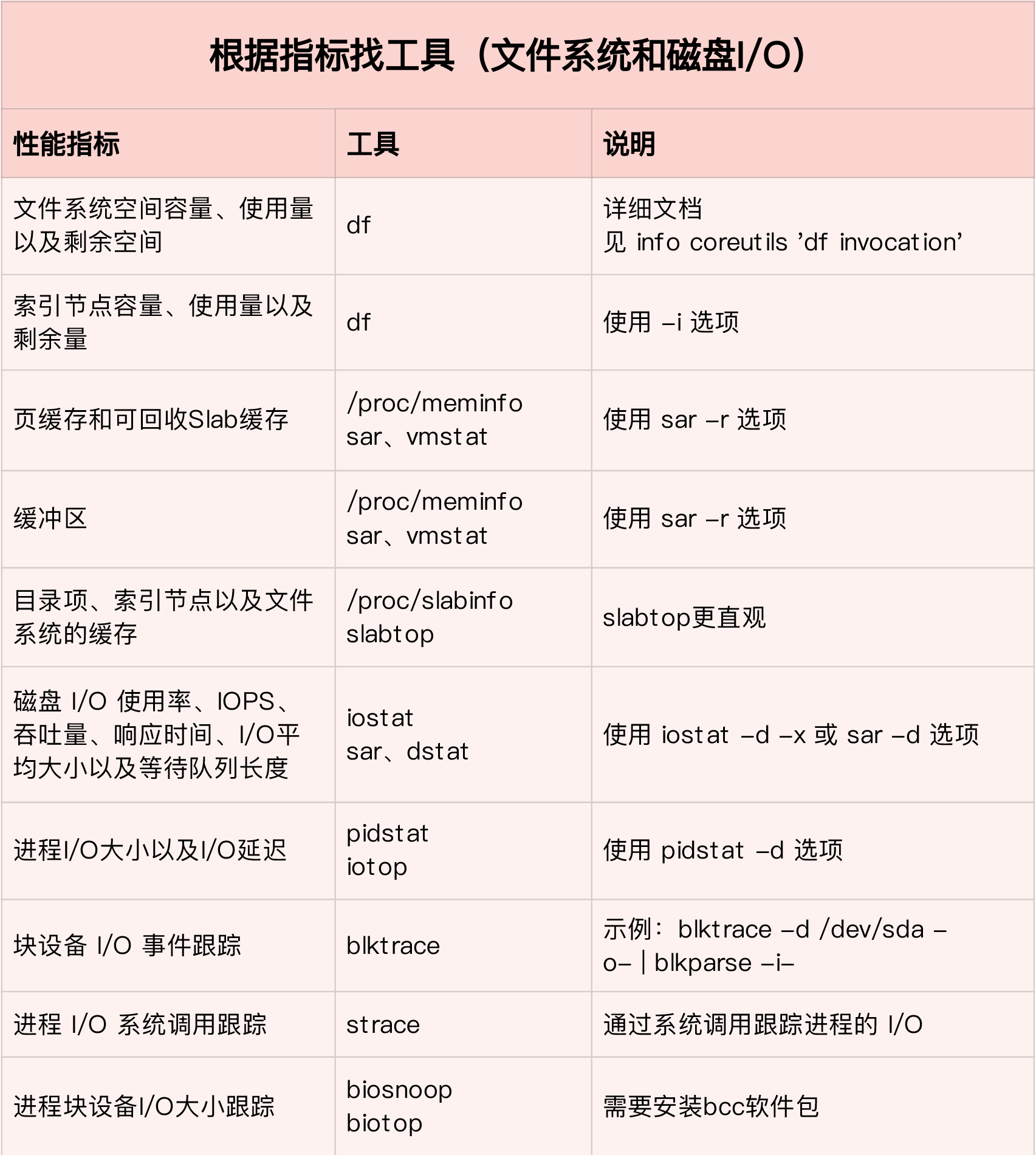
二. I/O性能指标及查询工具
磁盘性能的衡量标准经常用到的包括使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标是衡量磁盘性能的基本指标。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
2.1 磁盘I/O性能观测
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
1 | -d -x表示显示所有磁盘I/O的指标 |
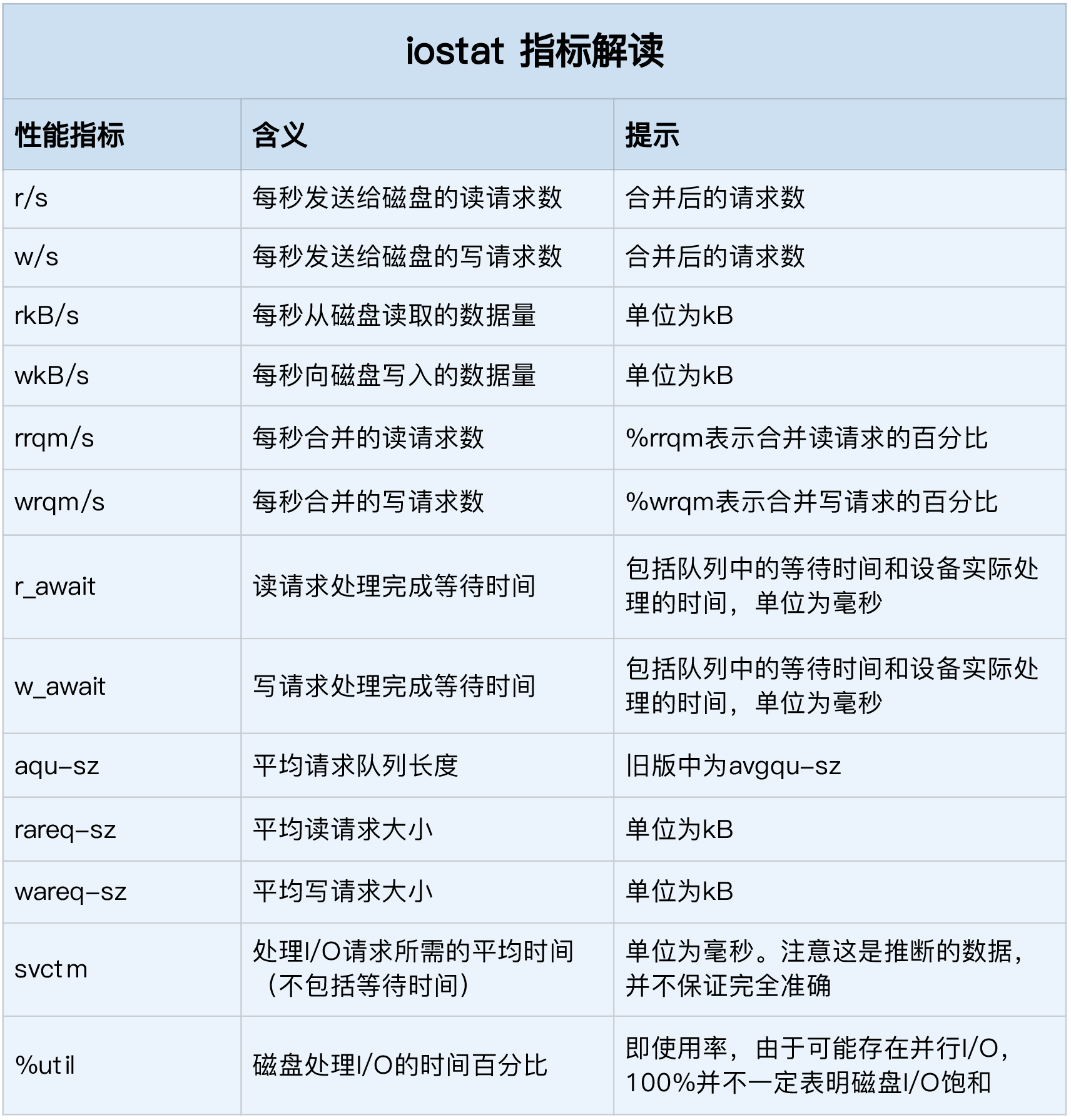
%util,就是我们前面提到的磁盘 I/O 使用率;r/s + w/s,就是 IOPS;rkB/s + wkB/s,就是吞吐量;r_await + w_await,就是响应时间。
从 iostat 并不能直接得到磁盘饱和度。事实上,饱和度通常也没有其他简单的观测方法,不过,你可以把观测到的平均请求队列长度或者读写请求完成的等待时间,跟基准测试的结果(比如通过 fio)进行对比,综合评估磁盘的饱和情况。
2.2df命令
df 命令能查看文件系统的磁盘空间使用情况,索引节点的容量(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
1 | df /dev/sda1 |
2.3 slabtop
内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了 Slab 的整体大小,具体到每一种 Slab 缓存,还要查看 /proc/slabinfo 这个文件。
1 | cat /proc/slabinfo | grep -E '^#|dentry|inode' |
/proc/slabinfo 的列比较多,具体含义你可以查询 man slabinfo。在实际性能分析中,我们更常使用 slabtop ,来找到占用内存最多的缓存类型。
1 | 按下c按照缓存大小排序,按下a按照活跃对象数排序 |
2.4 进程I/O检测
iostat 只提供磁盘整体的 I/O 性能数据,缺点在于并不能知道具体是哪些进程在进行磁盘读写。要观察进程的 I/O 情况,可以使用 pidstat 和 iotop 这两个工具进行检测。
1 | pidstat -d 1 |
iotop是一个类似于 top 的工具,可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
1 | iotop |
2.5 进程追踪
发现了可能存在I/O问题得进程后,我们可以使用strace -p来追踪指定进程的调用堆栈
1 | strace -p 18940 |
2.6 进程I/O文件使用
通过lsof工具,我们可以查看指定进程打开了哪些文件。注意这里-p后面必须跟进程pid,线程的无效。
1 | lsof -p 18940 |
2.7 内核读写检测工具
filetop基于 Linux 内核的 eBPF机制,主要跟踪内核中文件的读写情况,并输出线程 ID(TID)、读写大小、读写类型以及文件名称。filetop 输出了 8 列内容,分别是线程 ID、线程命令行、读写次数、读写的大小(单位 KB)、文件类型以及读写的文件名称。
1 | 切换到工具目录 |
2.8 open系统调用内核追踪
opensnoop 工具同属于 bcc 软件包,可以动态跟踪内核中的 open 系统调用。
1 | $ opensnoop |
2.9 nsenter容器追踪工具
nsenter和以上I/O工具配合,可以可以进入容器命名空间内部观测其I/O使用情况
1 | 由于这两个容器共享同一个网络命名空间,所以我们只需要进入app的网络命名空间即可 |
三. I/O压测工具
fio(Flexible I/O Tester)是最常用的文件系统和磁盘 I/O 性能基准测试工具。它提供了大量的可定制化选项,可以用来测试,裸盘或者文件系统在各种场景下的 I/O 性能,包括了不同块大小、不同 I/O 引擎以及是否使用缓存等场景。
1 | 随机读 |
direct,表示是否跳过系统缓存。上面示例中,我设置的 1 ,就表示跳过系统缓存。iodepth,表示使用异步 I/O(asynchronous I/O,简称 AIO)时,同时发出的 I/O 请求上限。在上面的示例中设置的是 64。rw,表示 I/O 模式。示例中,read/write分别表示顺序读 / 写,而randread/randwrite则分别表示随机读 / 写。ioengine,表示 I/O 引擎,它支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。上面示例中设置的libaio表示使用异步 I/O。bs,表示 I/O 的大小。示例中设置成了 4K(这也是默认值)。filename,表示文件路径,当然,它可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。示例中设置成了磁盘/dev/sdb。不过注意,用磁盘路径测试写,会破坏这个磁盘中的文件系统,所以在使用前一定要事先做好数据备份。
通常情况下,应用程序的 I/O 都是读写并行的,而且每次的 I/O 大小也不一定相同。所以,刚刚说的这几种场景,并不能精确模拟应用程序的 I/O 模式。那怎么才能精确模拟应用程序的 I/O 模式呢?幸运的是,fio 支持 I/O 的重放。借助前面提到过的 blktrace,再配合上 fio,就可以实现对应用程序 I/O 模式的基准测试。先用 blktrace ,记录磁盘设备的 I/O 访问情况;然后使用 fio ,重放 blktrace 的记录。这样就通过 blktrace + fio 的组合使用,得到了应用程序 I/O 模式的基准测试报告。
1 | 使用blktrace跟踪磁盘I/O,注意指定应用程序正在操作的磁盘 |
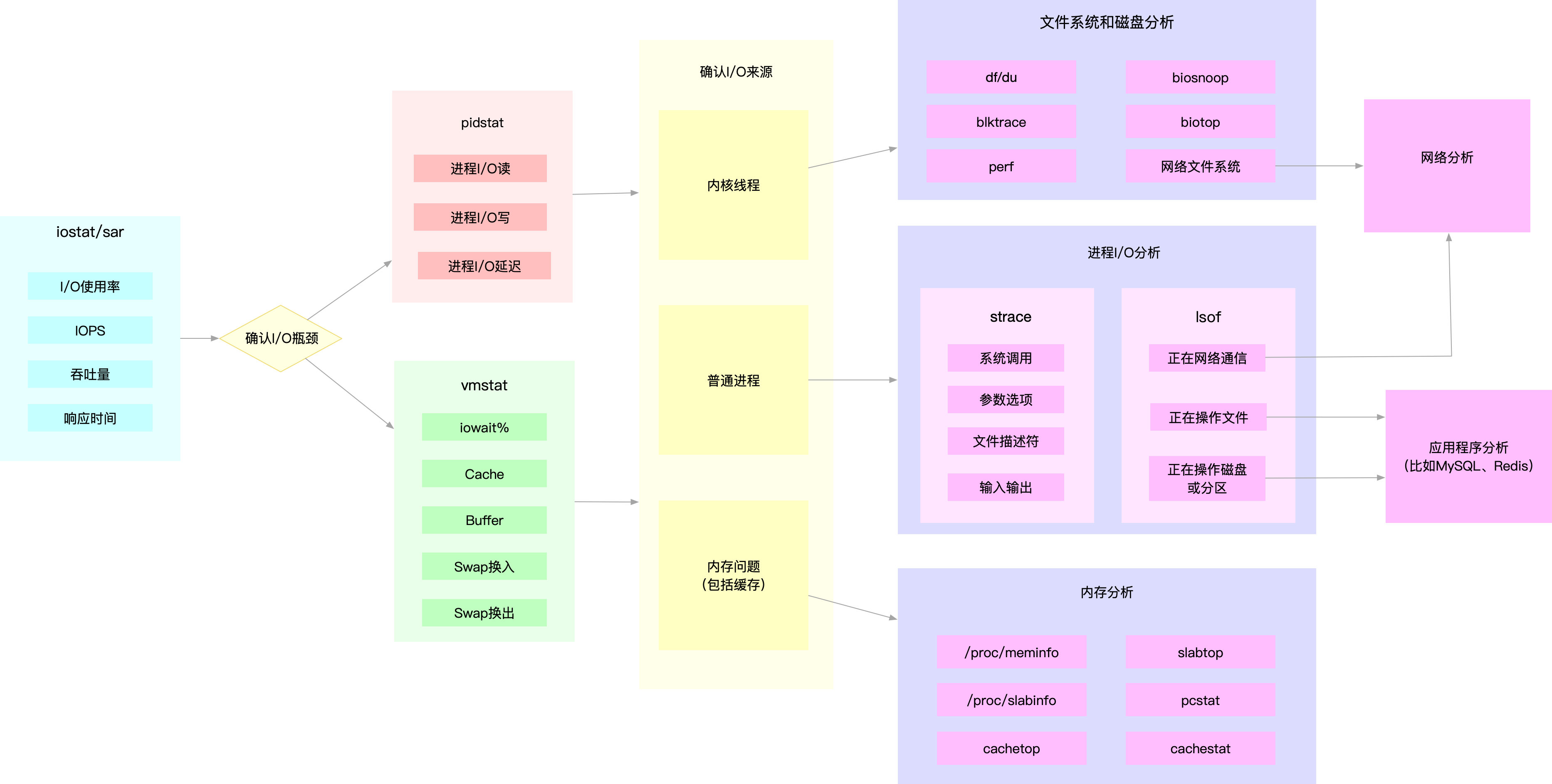
四. I/O性能优化思路
从 I/O 角度来分析,最开始的分析思路基本上类似,都是:
- 先用
iostat发现磁盘 I/O 性能瓶颈; - 再借助
pidstat,定位出导致瓶颈的进程; - 随后分析进程的 I/O 行为;
- 最后,结合应用程序的原理,分析这些 I/O 的来源。
4.1 应用层优化
应用层主要有以下常见优化点:
- 用追加写代替随机写,减少寻址开销,加快 I/O 写的速度
- 借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数
- 在应用程序内部构建自己的缓存,或者用
Redis这类外部缓存系统。这样,一方面,能在应用程序内部,控制缓存的数据和生命周期;另一方面,也能降低其他应用程序使用缓存对自身的影响。 - 在需要频繁读写同一块磁盘空间时,可以用
mmap代替 read/write,减少内存的拷贝次数 - 在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用
fsync()取代O_SYNC - 在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐使用
cgroups的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量 - 在使用 CFQ 调度器时,可以用
ionice来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。ionice支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
4.2 文件系统优化
文件系统主要存在以下优化点:
- 根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用
xfs文件系统。相比于 ext4 ,xfs支持更大的磁盘分区和更大的文件数量,如xfs支持大于 16TB 的磁盘。但是xfs文件系统的缺点在于无法收缩,而 ext4 则可以。 - 选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如
ext_attr、dir_index)、日志模式(如journal、ordered、writeback)、挂载选项(如noatime)等等。 - 优化文件系统的缓存。比如可以优化
pdflush脏页的刷新频率(比如设置dirty_expire_centisecs和dirty_writeback_centisecs)以及脏页的限额(比如调整dirty_background_ratio和dirty_ratio等)。再如还可以优化内核回收目录项缓存和索引节点缓存的倾向,即调整vfs_cache_pressure(/proc/sys/vm/vfs_cache_pressure,默认值 100),数值越大,就表示越容易回收。最后,在不需要持久化时还可以用内存文件系统tmpfs以获得更好的 I/O 性能 。tmpfs把数据直接保存在内存中,而不是磁盘中。比如/dev/shm/,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
4.3 磁盘优化
磁盘是整个 I/O 栈的最底层。从磁盘角度出发,自然也有很多有效的性能优化方法。
- 使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
- 针对磁盘和应用程序 I/O 模式的特征可以选择最适合的 I/O 调度算法。比方说,SSD 和虚拟机中的磁盘,通常用的是
noop调度算法。而数据库应用,我更推荐使用deadline算法。 - 对应用程序的数据,进行磁盘级别的隔离。比如可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
- 在顺序读比较多的场景中可以增大磁盘的预读数据,比如可以通过下面两种方法,调整
/dev/sdb的预读大小。- 调整内核选项
/sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。 - 使用
blockdev工具设置,比如blockdev --setra 8192 /dev/sdb,注意这里的单位是 512B(0.5KB),所以它的数值总是read_ahead_kb的两倍。
- 调整内核选项
- 优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度
/sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。 - 磁盘本身出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时还需要确认,磁盘本身是不是出现了硬件错误。比如可以查看
dmesg中是否有硬件 I/O 故障的日志。 还可以使用badblocks、smartctl等工具,检测磁盘的硬件问题,或用e2fsck等来检测文件系统的错误。如果发现问题,可以使用fsck等工具来修复。
总结
本文大致总结了磁盘I/O相关的性能指标、检测工具、压测工具以及优化思路。
参考文献
[1] Linux-insides
[2] 深入理解Linux内核
[3] Linux内核设计的艺术
[4] 深入理解计算机系统
[5] 深入理解Linux网络技术内幕
[6] shell脚本编程大全
[7] 极客时间 Linux性能优化实战
[8] 极客时间 系统性能调优必知必会

